
[그게 뭔가요] 생성AI 환각 줄이는 ‘RAG’
생성 인공지능(AI) 기술의 확산 속에서 항상 문제로 지적되는 게 바로 ‘환각’ 이슈다. 거대언어모델(LLM)이 잘못된 정보를 진짜인 것처럼 뽑아내고, 애먼 정보를 제시하는 부작용은 생성AI를 십분 믿지 못하게 만드는 요소로 작용한다.
기업도 마찬가지다. 특정 비즈니스 영역에 특화한 프라이빗 LLM 사용 요구가 증가하는 가운데 ‘검색 증강 생성(RAG)’ 기술이 각광받고 있다. 환각을 줄이는 열쇠로 불리는 RAG는 어떤 기술이고 또 관련 솔루션은 무엇이 있는지 살펴본다.
환각의 해결사?

RAG를 살펴보기 전에 먼저 생성AI가 환각을 불러일으키는 이유를 알아야 한다. 만능처럼 여겨지는 시장의 시선과 다르게 LLM 기반 AI 챗봇은 잘못된 답변을 내는 일이 빈번하다. 질의가 담은 의미를 잘못 파악해 오답을 내거나, 아예 관련 데이터를 학습하지 못해 동떨어진 답을 제시하는 등 챗GPT를 써본 이들이라면 이미 익숙한 경험이다.
LLM은 파라미터와 토큰 규모에 따라 답변 패턴이 달라진다. 사람이 여러 단어를 조합해 다양한 패턴의 문장을 만드는 것처럼, LLM의 답변 패턴은 파라미터, 토큰 규모와 일정 부분 비례한다. 반대로 이야기하면 LLM은 학습 데이터와 성능 범위 밖의 답변은 부정확할 수 있다는 뜻도 된다.
그냥 지식 검색이나 재미 차원이라면 사실 큰 문제는 아니다. 그러나 기업 비즈니스라면 이야기가 다르다. 잘못된 정보에 따른 오판이나 틀린 의사결정은 크게는 시장의 신뢰를 저버리는 단초가 된다. 이는 역설적으로 RAG를 주목하게 만들었다.

RAG란
RAG는 데이터의 정확도를 높여 이러한 환각을 없애는 데 초점을 맞춘 기술이다. AI 기업 코히어(Cohere)의 패트릭 루이스(Patrick Lewis) 박사가 처음 이 용어를 고안한 것으로 알려졌다. ‘Retrieval Augmented Generation’. 우리말로 검색 증강 생성이라고 칭하는데 여기서는 ‘증강’이 핵심이다.
이미 학습된 생성AI 모델의 한계를 외부 데이터베이스로 메꾼다. 관련성이 높은 정보를 증강해 더 적확한 정보를 준다. 관련 데이터가 들어있는 데이터베이스를 연결하고, 원천 정보에서 더 정확한 답을 끌어내는 게 바로 RAG다. 제품이나 서비스에 대한 특정 정보를 활용해 범용 LLM을 단독으로 쓰는 것보다 더 정확한 답변을 얻는 게 목적이다.
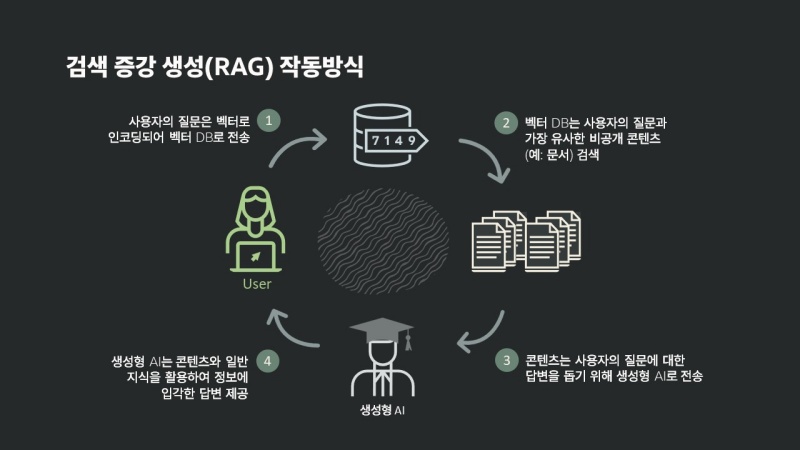
기본적인 구조는 이렇다. 사용자가 질의를 넣으면 먼저 LLM 자체 데이터를 확인한다. 또한 해당 업무 정보가 담긴 데이터를 추가로 검색하고, 질의 의도에 맞는 항목이 있으면 이를 사람이 이해하기 쉬운 자연어로 바꿔 답변하는 형태다.
물론 LLM에 더 많은 데이터를 학습시키는 것도 좋겠지만 프라이빗 LLM은 말 그대로 특정 업무에 활용하는 게 목표다. 굳이 LLM를 파인튜닝하는 것보다 RAG로 원하는 정보를 빠르게 찾는 게 더 효과적이다. 책 전체를 읽기보다는 어떤 한 단원만 제대로 공부시키는 것을 생각하면 쉽다.
벡터가 열쇠라는데…
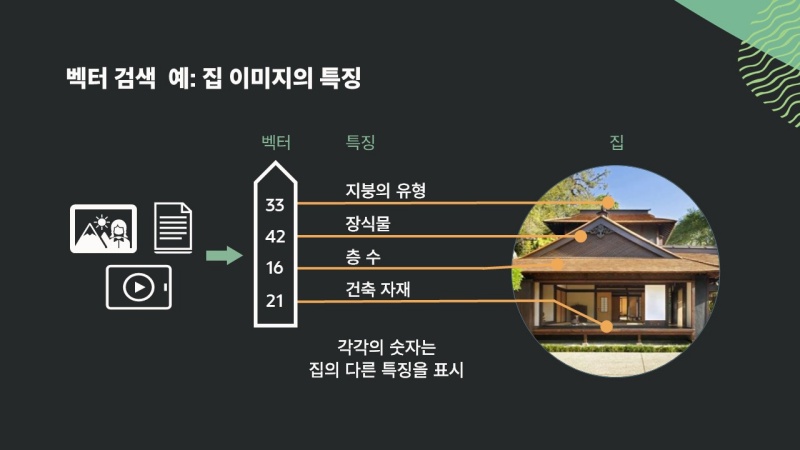
효과적으로 RAG를 돌리기 위한 도우미가 바로 ‘벡터(Vector)’다. 벡터화는 정형, 비정형 등 다양한 포맷의 데이터를 숫자로 표현하는 것을 말한다.
기업의 업무 가이드라인이나 내부 블로그, 인트라넷 게시글, 결제 문서 등 조직의 데이터를 데이터베이스에 벡터화해 넣어두면 생성AI는 그 정보에 맞춘 대답을 할 수 있어 일반 LLM보다 더 정확한 답변이 가능해진다. 정형 데이터뿐 아니라 이미지, 음성 등 비정형 데이터도 쉽게 검색할 수 있어 정확도를 높여주는 요소가 된다.
장성우 한국오라클 전무는 “현재의 생성AI는 허언증이 되는 경우가 있다”며 “또한 실시간 데이터를 확인할 수 없는 것도 한계로 지적되는 상황에서 RAG는 이를 해결할 수 있는 방안 중 하나”라고 말했다.
실제로 다수의 데이터베이스관리시스템(DBMS) 제공사들은 자사 DBMS에 벡터 지원 기능을 넣는 추세다. 특히 오라클 23C는 ‘AI 벡터 서치(Vector Search)’ 기능을 기본으로 지원해 시장의 관심을 끌었다. 네이버 또한 ‘Cloud DB for 포스트그레(Postgre)SQL’에 벡터 DB 지원 기능을 넣고 하이퍼클로바X의 활용도를 높이기로 했다.
RAG의 이점
LLM을 훈련하는 것보다 최신 정보를 반영하는 데 유리하다.
데이터베이스 업데이트로 LLM을 파인튜닝하는 것보다 더 적확한 데이터를 뽑아낼 수 있다.
잘못된 답변이 나오면 벡터 DB 안의 정보를 수정하거나 삭제해 정확도를 높일 수 있다.
사용 사례
이미 다양한 기업들이 RAG를 접목한 생성AI를 활용하거나 관련 서비스를 선보이고 있다. 베스핀글로벌은 자사의 대화형 AI 플랫폼 ‘헬프나우(HelpNow)에 RAG를 접목했고, 로앤컴퍼니 또한 판례 제공 서비스인 ‘빅케이스GPT’에 RAG를 적용했다.
로앤컴퍼니 측은 “국내 판례 329만건 중 정보 가치가 높은 판례들을 중심으로 벡터화한 데이터베이스를 구축함으로써 질의에 최적화된 답변을 내놓도록 설계했다”고 설명했다.
글. 바이라인네트워크
<이진호 기자>jhlee26@byline.network