

HWP 읽는 구글 제미나이, AI 생태계 한글 데이터 급증할까

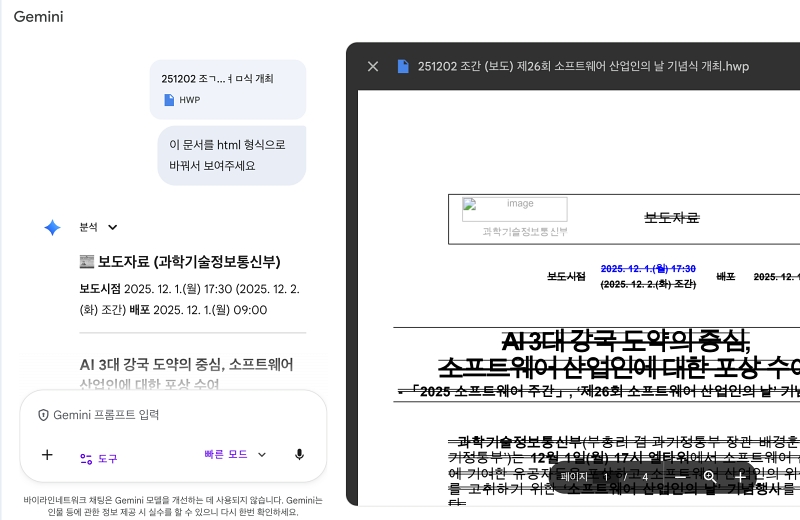
구글이 지난달 내놓은 플래그십 인공지능(AI) 모델 ‘제미나이3’가 한글과컴퓨터 워드프로세서인 ‘한글’의 독자 문서 포맷 ‘hwp’ 파일의 내용을 인식하는 것으로 알려졌다. 구글은 한글과컴퓨터와 별도 협력 없이 자체적으로 hwp 포맷의 데이터를 추출하고 표출하는 기능을 구축해 제미나이에 집어넣었다.
최근 업계에 따르면, 구글 제미나이3부터 hwp 포맷 문서 내부의 텍스트, 표 등 정보를 이해한다. 구글 제미나이에서 hwp 포맷의 문서를 업로드하고 요약이나 분석을 요청하면 내용을 이해해 답변해준다. 이같은 기능은 제미나이2.5 버전부터 hwp 인식을 지원했으나, 제미나이3에서 더 완벽한 이해를 보여준다.
문서 파일 속 텍스트, 표, 그래프 등의 정보를 AI 모델에서 이해하려면 파일의 내부 구조를 분석하는 파싱(parsing)을 거쳐야 한다. hwp는 바이너리 압축 기술이기 때문에 한컴에서 사용하는 hwp 압축 알고리즘 없이 컴퓨터로 읽을 수 없다. 별도의 프로그램을 설치하지 않으면 윈도우, 맥, 스마트폰 등의 파일탐색에서 hwp 포맷의 미리보기도 불가능하다.
hwp는 한국 문서 시장에서 강력한 기술적 해자였다. 2000년대 마이크로소프트도 오피스 제품을 한국 시장에 판매할 때 아래아한글의 장벽에 막혀 시장 확산에 어려움을 겪었다. 당시 마이크로소프트는 별도 개발조직을 한국지사에 설치하고 hwp 문서 변환도구 ‘HwpConverter’를 만들었다. 무엇보다 1990년대 중반부터 정부부처, 공공기관, 학교 등의 워드프로세서가 아래아한글로 고착화돼 hwp 파일을 읽을 수 없는 마이크로소프트 워드의 경쟁력이 제한적이었다.
한컴은 2010년부터 hwp 포맷의 문서 구조를 일반에 공개했다. hwp 파일 내부의 특정 데이터스트림이 zlib 압축 알고리즘을 사용한다는 게 이때부터 알려졌다. 한컴은 이와함께 XML 기반으로 개방형 포맷인 ‘hwpx’ 포맷을 내놓기도 했다. hwpx는 국제표준인 ZIP 압축 방식을 따른다.
한컴이 hwp 포맷의 구조 문서를 공개하고 있지만, 한글 워드프로세서 버전이 업그레이드되면 hwp 포맷도 바뀌어 컴퓨터에서 완전히 인식하지 못하는 문제는 이어지고 있다.
구글은 제미나이에서 hwp 포맷을 인식할 수 있게 만들기 위해 한글과컴퓨터와 별도 협력을 하지 않은 것으로 확인됐다. 공개된 hwp 포맷 구조 문서와 내부 데이터 추출 기술을 활용한 것으로 보인다.
문서 파일 내 데이터를 AI 모델이 인식하게 하려면 문서에서 데이터를 추출한 후 AI 모델에서 이해할 수 있는 txt나, xml 기반 포맷으로 변환해 학습시키고 추론 단게에서 재구축하는 과정이 필요하다.
핵심은 ‘문서 파서(document Parser)’ 기술이다. OLE2 컨테이너 구조, 내부 zlib 압축 알고리즘 등을 해독하는 전용 파서를 이용해 압축 해제하고, 텍스트를 비록한 모든 문서 내 편집 정보를 추출한다. 제미나이의 레이아웃 파서는 문서의 계층 구조와 시각 요소를 이해한다. 파서로 추출된 데이터는 청크(Chunk)로 나뉘어 제미나이3 모델에 입력되고 답변 작업에 활용된다.
한글과컴퓨터 측은 “제미나이3의 hwp 지원은 한컴의 지속적인 포맷 개방화 노력과 구글의 한국어 데이터 처리 역량 강화가 맞물린 결과”라며 “한컴이 2021년부터 개방형 포맷인 HWPX를 기본으로 전환하고 관련 기술 문서를 공개해온 것이, 구글과 같은 빅테크가 별도 협약 없이도 기술적으로 지원할 수 있는 토대가 됐다”고 밝혔다.
또한 “한컴은 구글과 함께 구글 워크스페이스 고도화와 같은 협업 포인트를 다방면으로 추진 중”이라고 덧붙였다.
그동안 hwp와 한컴은 우리나라 AI 발전을 가로막는 장애물로 인식됐다. 국내 공공문서 91% 이상을 차지하는 hwp 포맷 문서는 1990년대부터 30년 이상 대규모로 저장돼왔지만, 컴퓨터가 이해할 수 없는 데이터로 평가절하됐다.
제미나이가 글로벌 소프트웨어나 서비스에서 hwp 포맷을 지원한 첫 사례는 아니다. 이미 드롭박스는 2023년부터 드롭박스에 업로드된 hwp 문서를 별도 뷰어나 파일 변환 없이 웹브라우저에서 바로 볼 수 있는 ‘미리보기’ 기능을 제공중이다. 드롭박스 미리보기 상태에서 텍스트 검색도 가능하다. 이는 일반 사용자 측면의 hwp 접근성을 높인 것이어서 AI 모델 개발과 활용과 조금 다른 문제다.
제미나이3의 hwp 파일 지원은 국내 데이터 시장에 큰 전환점일 수 있다. 일단 hwpx나 pdf로 만들어지지 않은 구형 hwp 문서가 손쉽게 AI 학습용 데이터로 활용될 수 있게 됐다. AI 모델의 학습에 필요한 데이터 확보는 AI 기술 경쟁력의 핵심이다. 수십억건에 달할 것으로 추정되는 국가기록물 전자문서 데이터가 AI 생태계에 유입될 수 있는 조건이 마련된 것이다.
일반 사용자도 hwp 문서를 AI 모델에서 활용하기 위해 별도의 복사/붙여넣기 작업이나 pdf 출력을 거치지 않아도 돼 AI 활용 편의성이 향상될 것으로 예상된다.
한컴 측은 “이번 조치로 HWP 문서가 글로벌 AI 생태계에 본격적으로 편입됨에 따라, 공공 및 기업의 방대한 한글 문서 데이터가 AI 학습 및 분석의 핵심 자원으로 재평가 받게 될 것”이라며 “한컴 데이터 로더는 단순 열람을 넘어 문서 데이터를 전문적으로 가공하고 AI 학습 최적화를 제공합하며, 한컴은 나아가 데이터 로더를 포함한 AI 사업 기회도 더욱 확대될 것으로 기대한다”고 강조했다.
제미나이3에서 hwp 포맷을 바로 활용할 수 있다고 해도 모든 장애물이 걷힌 건 아니다. 우리나라 공공 문서의 경우 기관, 부서, 개인마다 독자적이고 복잡한 서식을 사용하기 때문에 데이터 파서를 구현하는 게 매우 까다롭다. 예를 들어, 표로 만들어진 항목의 경우 셀 안에 2차, 3차의 표를 넣기도 한다.
글. 바이라인네트워크
<김우용 기자>yong2@byline.network