토스가 안정적으로 서버를 운영하는 방법
토스는 50여개 서비스를 제공하는 모바일 금융 플랫폼이다. 누적 사용자는 1900만명으로, 매월 1000만명 이상이 사용하고 있다. 사용자도, 서비스 수도 많은 토스는 서버를 어떻게 운영하고 있을까.
결론부터 말하면, 토스는 전통적인 금융기업보다 인터넷기업과 비슷한 인프라 구조를 채택했다. 또 데이터센터 이중화로, 두 개의 데이터센터에서 서비스를 운영하고 있다. 일부 서비스는 아마존웹서비스(AWS)를 활용하고 있다. 일반적으로 두 개의 데이터센터를 운영할 경우 여러 컴포넌트에서 운영이슈가 발생하곤 한다. 토스는 지금까지 쌓아온 노하우를 바탕으로 안정적으로 서버를 운영하는 방법을 자체 개발자 컨퍼런스 ‘슬래시21’에서 공유했다.
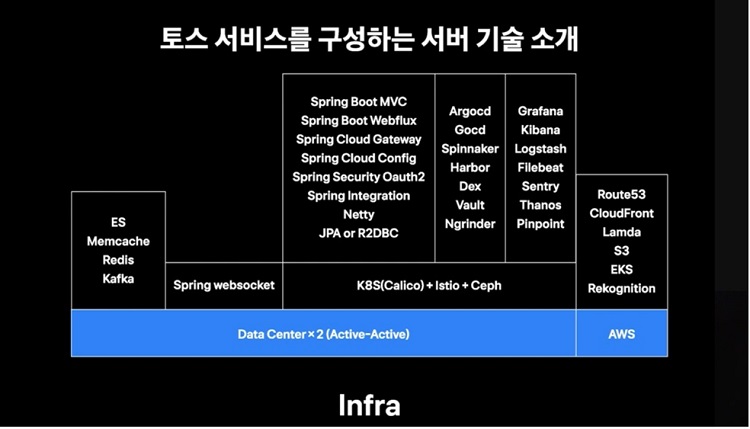
토스의 서비스는 마이크로서비스아키텍처(MSA)로 구성되어 있어 서버가 많다. 많은 양의 서버를 관리하고, 효율적으로 인프라를 활용하기 위해 쿠버네티스를 컨테이터 오케스트레이션으로 도입했다.

또 캘리코(calico) cni, 서비스 매시, 이스티오(Istio)를 채택했다. 민감한 자료는 오픈소스 소프트웨어 스토리지 플랫폼인 Ceph에 저장하고 있다.
토스에는 송금 외에도 은행과 연동되는 서비스가 많다. 송금 이후 채팅할 수 있는 서비스, 카드사 알림, 은행 대출 추천 등 외부 연동 서비스가 많다. 홈탭이나 내소비 등 여러 서비스의 데이터를 모아 보여주기도 한다.
토스는 여러 서비스 특성에 맞춰 스프링(Spring) 계열의 프로젝트를 선택해 개발하고 있다. 개발언어는 과거 자바를 많이 사용했다면, 최근에는 코틀린을 주로 사용하고 있다. 클라우드 서비스인 AWS는 도메인네임시스템(DNS)를 설정하거나 이미지 검수, 스태틱파일을 서빙하는 기능으로 활용하고 있다.
이항령 토스 서버 플랫폼팀 리더는 “데이터 센터 두 곳을 운영하며 평상시에는 트래픽이 50:50으로 들어가지만, 한쪽이 100%가 되도록 트래픽을 옮기는 작업을 자주 한다”며 “데브옵스(DevOps) 팀에서도 자동화를 해뒀다”고 설명했다.
트래픽을 한 쪽으로 옮기는 이유는 크게 두 가지다. 문제가 해결된 다음에야 장애가 복구된다면, 장애시간이 오래 걸릴 수밖에 없다. 따라서 해결보다 복구를 중심으로 대응한다. 장애가 나지 않은 반대편 데이터 센터로 트래픽을 옮긴다면, 장애시간을 줄일 수 있다는 설명이다.
다만, 토스 측은 새로운 시스템을 도입하거나 쿠버네티스 설정을 변경할 때 수차례 테스트를 하고 예상 문제를 확인하지만, 문제가 발생할 가능성이 0%는 아니라고 강조했다. 최소한의 장애 가능성을 줄이기 위해 트래픽을 한쪽으로 옮기고 난 뒤 설정을 변경한다.
이 리더는 “적은 트래픽으로 문제가 없다면 점진적으로 늘려가고, 문제가 발생하면 바로 트래픽을 제거해 장애를 겪는 고객 수를 최소화하고 있다”며 “서비스 배포를 데이터 센터에 적용했다고 보면 된다”고 설명했다.
로그를 활용한 모니터링
MSA 구조로 인해 서버들이 여러 곳에서 뜨는 만큼, 토스는 로그의 중앙집중화가 필요하다고 판단했다. 로그백, 파일비트를 통해 애플리케이션 로그를 아파치 카프카(Kafka)로 보내고, 데이터시각화 대시보드에서 검색해 볼 수 있도록 했다.
로그에는 메시지를 포함한 다양한 데이터가 포함된다. 컨테이너ID와 서비스ID로 어느 데이터센터에서 어떤 컨테이너가 로그를 남겼는지 등을 확인할 수 있다. 보통 이 데이터로 특정 장비의 문제인지, 특정 서비스의 문제인지 구분할 수 있다는 것이 토스 측의 설명이다.
배포ID는 어느 배포 버전에서 발생하는 로그인이 알려주며, 신규 혹은 이전 배포에서 발생하는지 확인할 수 있다. 만약 에러로그가 신규 배포에서만 발생할 경우 바로 롤백한다.
또 금융회사로 5년간 장기 보관해야 하는 데이터는 카프카에서 하둡으로 데이터를 쌓아 장기보관하고 있다.
이 리더는 “로그는 데이터센터 급 장애가 발생한 상황에서도 서비스 개발자들이 확인할 수 있어야 하기 때문에 이중화되어 있다”며 “ES의 경우 데이터센터별 50대씩 100대 정도 운영 중이며, 하루 15TB 상당의 로그가 쌓이고 있다”고 밝혔다.
토스가 서버 인프라를 모니터링하는 방법
토스의 서버 인프라는 서비스가 늘면서 더욱 복잡해졌다. 지난 2019년 토스의 서버 인프라에 올라간 마이크로서비스 종류는 130개에서, 현재 236개로 늘어났다. 시스템은 비즈니스 니즈와 보안 목표 등에 따라 변하기 때문에 새로운 이슈를 해결하며 운영해야 한다는 것이 토스의 인프라 운영 방침이다.
현재 토스는 컨테이너 기반의 오케스트레이션 시스템을 서버 인프라로 사용하고 있다. 지난 2019년 VAMP, DC/OS 기반의 인프라에서 이스티오와 쿠버네티스 환경으로 마이그레이션을 진행했다.
마이그레이션 이후 메인 모니터링 시스템은 프로메테우스로 바뀌었다. 운영의 편리성을 돕는 타노스도 메인 모니터링으로 자리 잡았다.
CPU의 경우 컨테이너에서 리눅스 CPU 알고리즘 양을 측정할 수 있어, CPU의 포화상태를 확인할 수 있다. 메모리는 컨테이너 측면에서 메모리 사용 여부를 판단한다. 디스크 디바이스는 각 애플리케이션이 읽고 쓰는 것을 얼마나 많이 하는지, OS 측면에서 디스크 전체 활용과 에러 여부 등을 확인한다.
토스의 서버 인프라 모니터링 발표를 맡은 이재성 토스코어 데브옵스 엔지니어는 “종합하면 네트워크 제어권을 강화해 네트워크 문제를 진단할 수 있는 메트릭을 강화했다”며 “발생이슈와 메트릭 사이의 상관관계를 높이고 모니터링 인프라도 스케일 아웃이 가능하도록 구성을 발전시키는데 노력했다”고 전했다.
이어 “사실 요구사항의 난이도가 올라갈 테니 끝이 없는 문제”라며 “앞으로도 계속해서 좋은 메트릭을 만들고 상관관계를 찾아내 빠르게 문제를 해결해나갈 것”이라고 밝혔다.
글. 바이라인네트워크
<홍하나 기자>0626hhn@byline.network
첫 댓글