대학생에게 홈쇼핑 데이터를 주면 매출을 예측할 수 있을까? SAS 분석 챔피언십 ① 동국대 팀
대학생에게 특정 홈쇼핑의 데이터를 주면 그다음 해 매출을 예측할 수 있을까? SAS코리아에서 진행한 제17회 SAS 분석 챔피언십 이야기다. 17회를 맞은 SAS 분석 챔피언십은, 현업이 아닌 대학생에게 현업의 데이터를 주고 분석하도록 하는 대회다. 17회의 후원 기업은 롯데홈쇼핑으로, 롯데홈쇼핑의 실제 매출 데이터로 2018년 매출을 예측하도록 했다. 주어진 데이터는 2013년부터 2017년까지의 판매 상품 정보, 프로그램 실적, 프로그램 편성 정보, 편성 시간표 등이다. 편성정보나 실적에는 쇼 호스트나 PD, 매출액 등이 표기돼 있다.
동국대 통계학과 팀 ‘꾸준한 변수 탐색’
대상을 받은 동국대 팀의 전략은 다양한 파생변수를 촘촘히 쪼개 모델링하고, 이를 시각화해 데이터를 판단하는 방식이다. 우선 동국대 팀은 학과 내 빅데이터 학회 비어플 출신으로, 지난해에도 선배들이 대상을 수상한 바 있다. 팀의 오지수 학생은 “SAS 분석 챔피언십은 EDA(Exploratory Data Analysis, 탐색적 데이터 분석) 과정도 활용방안만큼 매우 중요하게 여긴다”는 이유로 참가를 결정했다고 했다.

이상치와 결측치 제거
우선 변수를 만들기 전, 무의미한 낭비를 막기 위해 결측치나 이상치를 제거했다.
롯데홈쇼핑에는 ‘핫 초이스’로 부르는 사전 녹화방송이 있다. 쇼 호스트나 PD가 나오지 않는 방송이다. 이는 매출 예측에 도움이 되지 않는다고 판단해 결측치 처리했다. 고정방송은 스타 쇼 호스트인 정윤정 씨가 등장하는 ‘정쇼’와 같은 방송을 말하는데, 함께 진행하는 PD가 고정돼 있으므로 매출 예측보다는 단순 통계만으로도 예측 가능하다고 생각해 결측치 처리했다. 이러한 현상은 연예인이 등장하는 ‘최유라쇼’와 ‘퐝규의 밥상’ 등에도 동일하므로 역시 결측치 처리했다.
이상치의 경우 매출액이 0원으로 잡히는 렌털이나 상담 상품은 예측 목표에 포함되지 않았으므로 삭제했으며, 과거엔 인기 있다가 점점 판매량이 줄어들다 2017년에 들어서는 거의 판매되지 않는 상품 역시 이상치로 판단해 제거했다.
변수 탐색과 파생변수 생성
변수탐색에서는 동국대 팀의 집념을 느낄 수 있다. 고정으로 만든 변수는 방송정보 변수와 상품정보 변수다. 이 안에서 다양한 파생변수를 만들어냈다. 박태렬 학생은 “주어진 변수들의 90% 이상이 범주형 변수였기 때문에 매출액의 분산을 줄이는 방향으로 분석을 진행했다”며, 재범주화 기준에서 많은 고민을 했다”고 전했다. 실제로 동국대 팀은 거의 모든 변수를 재범주화하는 끈기 있는 모습을 보였다.
우선 방송정보 변수에서는 기본적인 연도, 월, 일, 요일을 만들었다. 이후 방송 시간의 중간을 기점으로 방송 중간시간 파생변수를 만든다. 이 중간시간을 반올림해 중간Hour 변수를 만들었다. 예를 들어 11시 23분이면 11시로 사용한다. 드라마 등 인기방송이 끝날 시점에 시청자들이 채널을 돌리는 시간(재핑타임)을 책정하기 위한 변수다. 또한, 휴일이 며칠 지속되냐(하루 혹은 이틀)를 다르게 범주화한 공휴일 변수, 일주일을 168개의 시간으로 쪼개 범주화한 시간 변수, 1주를 통으로 측정하는 주 변수, 인기 상품이 팔리는 프라임 시간대를 요일별로 또다시 쪼갠 프라임 범주형 변수들을 도입했다. 프라임 시간대는 월수금을 한 묶음으로, 나머지 요일은 따로 책정했다.
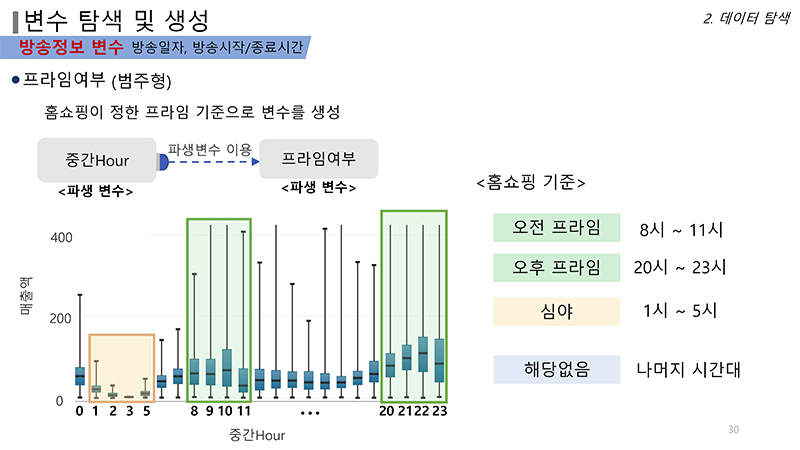
또한, 쇼 호스트와 PD의 판매능력이 매출에 영향을 미친다는 가정하에 각 쇼 호스트와 PD의 매출액 능력을 산정하는 SH와 PD 변수를 만들었다. 이외에 최유라쇼, 퐝규의밥상 등은 프로그램명을 기준으로 변수화했다.
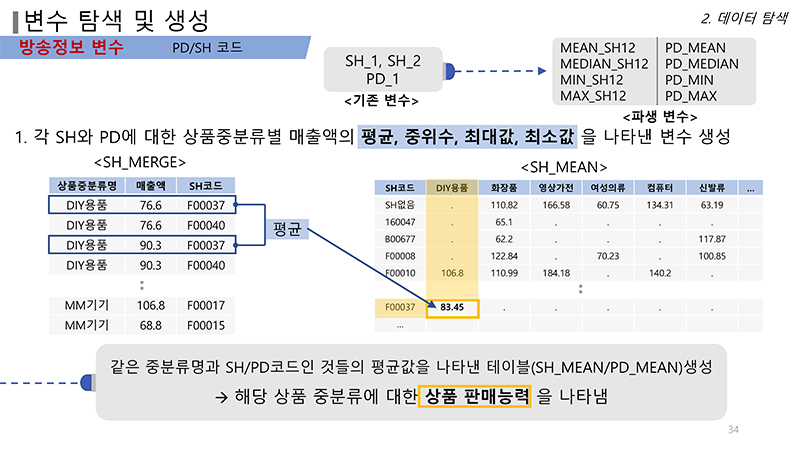
상품 정보 역시 변수화했다. 롯데홈쇼핑이 제공한 자료에는 상품 대분류, 중분류, 소분류와 세분류가 있었는데 이중 대중소분류를 상품대분류 코드로 파생변수화했다. 세분류의 경우 제품 코드가 존재하므로 상품분류 변수를 따로 잡았다. 이 과정에서 시스템 부엌 등 매출액이 다른 제품보다 압도적으로 높은 제품은 따로 범주화했다고 한다.
이외에도 판매량이 높은 브랜드가 있어 브랜드파워 변수를 만들었고, 방송 길이와 매출액에 연관이 있다고 생각해 그 방송 내에서 몇 개의 제품을 판매하는지를 연속형으로 범주화했다. 이는 방송길이/제품수 변수로, 3600초 방송에서 두개 제품을 팔았으면 변수의 값은 1800이 되고 각각 매출액을 예측했다. 또한, 1년 매출을 예측해야 하므로 특정 상품의 시즌성 매출에서 힌트를 얻을 수 있을 것으로 판단해 1년 전 같은 달 같은 시간대에 같은 상품을 팔았을 때의 매출액 평균값을 변수로 사용했다.
외부변수를 만들기 위해서는 실제 매출액과 얼마나 연관이 있는지 몰랐기 때문에 구할 수 있는 데이터는 모두 구했다고 한다. 예보데이터(일주일 전 날씨 정보)를 활용했는데, 이 중 전 국민의 총인구의 사는 지역만을 조사했다고 한다. 또한, 미세먼지, 강우량 등을 조사했다. 다른 방송국의 인기방송 시청률도 외부변수화했다. 이때 4만6000여개 방송 시간을 모두 기입했다고 한다. 인간이 데이터보다 위대함을 느낄 수 있는 대목이다. 외부 변수의 경우 시각화를 해서 실제로 매출에 영향이 있는지 살펴본 후 매출액과 연관이 있는 데이터만 분석에 활용했다.
이렇게 모은 데이터를 전처리하는 과정은 SAS 엔터프라이즈 가이드(SAS® Enterprise Guide®)를 사용했다. 박태렬 학생은 “코딩 없이 변수 생성, 변수 속성 변경, 값 대체, 회귀분석, 시각화 등을 사용할 수 있어서 편리했다”고 전했다.
데이터 시각화
SAS 바이야(SAS® Viya®) 플랫폼 기반 SAS 비주얼 애널리틱스(SAS® Visual Analytics)를 통한 데이터 시각화를 통해 변수를 데이터화했다. 이소윤 학생은 “필터로 나타내고 싶은 부분만 시각화를 할 수 있었던 게 좋았다”고 했다. 시각화 결과 유의미한 결과가 있었는데, 방송빈도 대비 매출이 큰 상품들을 워드 클라우드로 파악할 수 있었다. 방송빈도와 쇼 호스트·PD의 데이터를 비교해보자 쇼 호스트와 PD별 주력 상품이 나타났다. 방송빈도가 많은데 매출이 낮은 PD·쇼 호스트와 높은 이들을 가려내 쇼 호스트와 PD의 능력이 제품 판매에 영향을 주는 것임을 밝혀냈다.

또한, 특정 브랜드 5개의 판매량이 70%를 차지해 브랜드 신뢰성을 확인할 수 있었다. 동국대 팀의 한방이 된 프라임 시간대의 경우, 같은 프라임 시간대에도 요일별로 매출액 분포가 다름을 확인 가능했다. 따라서 프라임 시간과 요일을 가장 중요한 변수로 놓고 모델링을 시작했다고 한다. 이외에 재미있는 요소는 생활물가 지수와 매출액이 반비례한다는 것. 즉, 물가가 높아지면 매출액은 바로 떨어진다.
모델링
모델링 트레인 셋은 2013~2016년의 것으로 2017년 데이터를 검증했고, 최종모델은 2013~2017로 2018년 매출을 예측했다. 범주형 변수가 많으므로 선형회귀를 사용하지 않고 그래디언트 부스팅을 사용했다. 전체 데이터로 2017년 매출 예측 시 RMSE(평균 제곱근 오차, 모델이 예측한 값과 실제값의 차이를 알려주는 척도)는 30.592였다. 매출액이 매우 높거나 낮은 경우 오차가 컸는데, 오차를 살펴보니 오후 프라임 시간대인 것을 깨닫고 옵션값을 조정해 오버피팅(과적합)을 완화했다.
방송 시간대를 4가지로 분류해 모델링을 진행한 결과, 매출에 영향을 미치는 중요 변수가 서로 달랐다. 예를 들면 오후 프라임 시간대에서는 브랜드 신뢰도보다 쇼 호스트나 PD의 판매 능력이 훨씬 중요한 것으로 나타났다.
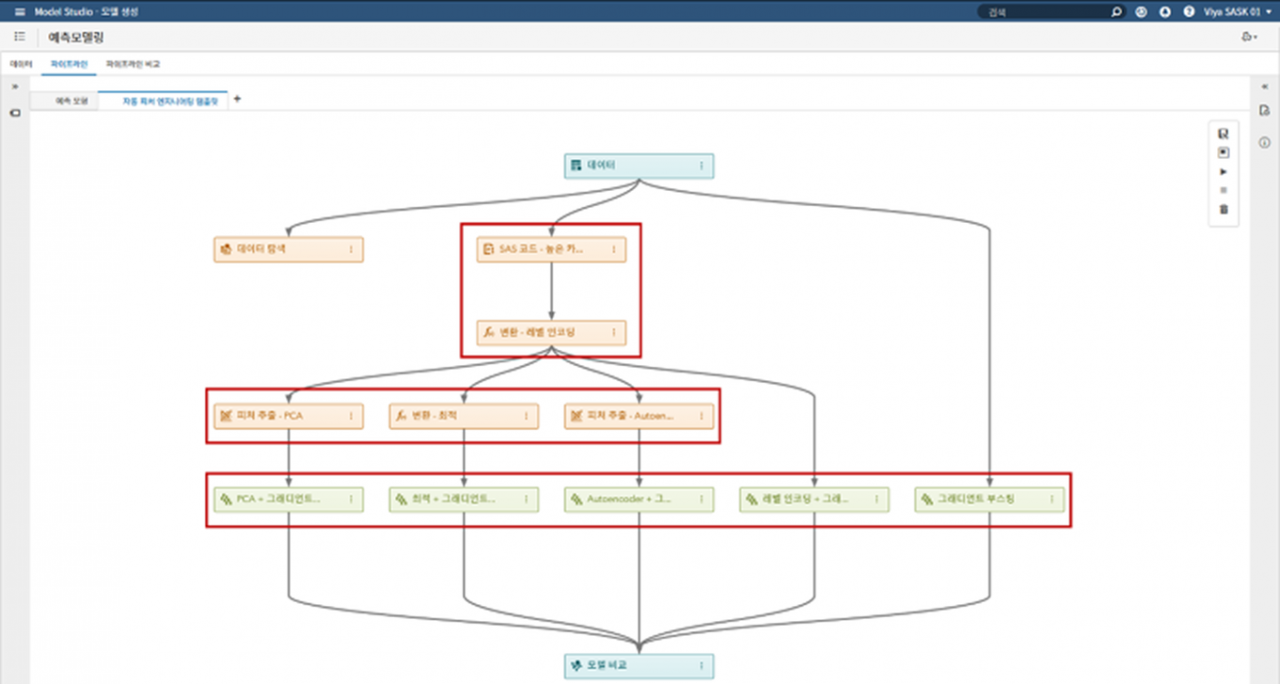
모델링의 경우 SAS 비주얼 데이터 마이닝 앤드 머신러닝(SAS® Visual Data Mining and Machine Learning; SAS VDMML)을 사용했다. 그래디언트 부스팅, 랜덤 포레스트, 의사결정나무, 포아송회귀와 같은 머신러닝 기법들을 클릭만으로 구현할 수 있기 때문이다. 수상했던 다른 팀(이화여대 팀)의 경우 코딩을 하나도 하지 않은 팀도 있었다고 한다.
활용방안
SAS 비주얼 애널리틱스를 통해 시각화된 자료를 보면 남성제품 매출액이 성장 중임을 확인할 수 있다. 그루밍족이 늘고 있는 만큼 높은 매출액을 기대할 수 있을 것이라고 동국대 팀은 전했다. 비슷한 이유로 건강상품 방송빈도가 늘고 있고 매출액 자체도 높다. 노령화 트렌드에 맞춘 상품이 필요하다.
홈쇼핑의 경우 4050을 타깃으로 한 가족 상품이 많지만 1인 가구를 위한 방송편성 역시 매출에 좋은 영향을 줄 것이다. 또한, 생활물가지수가 매출에 직접적 영향을 주므로 지수가 높아졌을 때 가격 경쟁력 있는 상품이 필요할 것이다.
동국대 팀 대상 수상 이유
동국대 팀은 홈쇼핑에 대한 지식을 잘 쌓은 것이 특징이다. 이상치 제거 등도 함부로 하지 않고 높은 이유를 굳이 찾아냈다. 분석과 변수, 모델링이 활용방안과 연계된 것이 특징이다. 예측정확도 역시 뛰어난 편이었으나 짧은 시간(2개월) 동안에도 여러 변수를 만들고 특히 외부데이터에 많이 접근해 분석 자료로까지 활용했다는 것이 훌륭하다. 특히 프라임 시간대의 경우 시각화에서 프라임 시간대를 요일별 네 개로 나눠 진행한 점이 대상을 타게 된 결과로 나타났다. 결국 과정이 논리적이고 과정에 따른 결과가 도출된 것이 대상을 탄 이유였다.

SAS 분석 챔피언십이란
기업에서 실제로 사용하는 데이터를 통해 학생들에게 실제 비즈니스 툴과 데이터를 추고 데이터를 예측하는 대회. 글로벌 비즈니스 분석 소프트웨어 기업인 SAS에서 매년 개최한다.
대학생에게 홈쇼핑 데이터를 주면 매출을 예측할 수 있을까? SAS 분석 챔피언십 ② 연세대 팀 보러 가기(클릭)
글. 바이라인네트워크
<이종철 기자> jude@byline.network
흥미로운 분석이었어요. 생활물가지수와 매출액이 서로 반비례한다는 부분이 궁금합니다. 둘 다 월 단위 측정인지, 계절적 요인을 제거한 것인지 등등요. 정말 그 둘이 반비례한다면, 쇼호스트 PD 등 내부 변수뿐만 아니라 날씨나 미세먼지 같은 외부변수들의 영향력도 미미하다는 이야기인가요?
안녕하세요. 분석 진행한 팀입니다.
생활물가지수는 월단위로 측정된 값으로 여러 부문으로 나뉘어서 측정된 값이었는데요.
솔직히 매출액과 큰 연관성이 없을 줄 알았는데, 월평균매출액과 월평균생활지수를 비교했을 때 유의미한 경향성을 보여서 놀랐었습니다.
하지만 물가지수가 급격히 변한 기간에만 반대의 경향을 띠었던 점을 알 수 있었고요.
계절적 요인이나 시즌성 요인을 제거하지 않은 상태에서 살펴본 것도 어느정도 영향이 있어보입니다.
또한 이 생활물가지수는 한달이 지난 후에야 발표되는 값이기 때문에 예측변수로는 사용할 수 없었고, 매출액 예측에는 분석결과 브랜드, 시간대, 쇼호스트/피디의 역량, 상품분류 변수들이 가장 중요한 변수로 꼽혔습니다.
날씨면에서는 비가 오는 날 오전 프라임시간대부터 점심시간대까지 10% 정도 높은 매출액을 보였고요. 16년부터는 미세먼지 농도가 높은 날 평균매출액이 유의미하게 높음을 발견할 수 있었습니다.
생활물가지수는 거시적으로 영향력을 끼침을 알 수 있었기 때문에, 홈쇼핑사에서 참고할만한 부분이라 여겨 활용방안으로 발표를 했었습니다.