
세이지메이커? 베드록?…골라 쓰는 AWS의 생성AI 플랫폼
편리함은 알지만 막상 제대로 도입하는 데는 여러 작업이 필요한 생성 인공지능(AI) 솔루션. 일반 사용자라면 챗GPT 같은 범용 모델을 바로 사용해도 크게 무리가 없지만 엔터프라이즈 환경이라면 이야기가 달라진다. 원하는 데이터를 넣어 학습시키고, 여러 기반모델(FM)을 한 곳에서 골라 바로 활용하는 등 업무 환경에 맞춘 사전 작업을 돕는 솔루션이 있다.
아마존웹서비스(AWS)는 머신러닝 작업을 지원하는 플랫폼 ‘세이지메이커 점프스타트(Sagemaker Jumpstart)’와 다양한 FM을 한 곳에서 지원하는 ‘베드록(Bedrock)’을 통해 엔터프라이즈 생성AI 활용을 지원하고 있다.
20일 서울 서초구 엘타워에서 열린 ‘AWS 유니콘 데이 2024’ 세션 발표에 나선 박진우 AWS코리아 솔루션즈아키텍트는 “세이지메이커 점프스타트를 활용하면 원하는 FM을 손쉽게 학습시켜 활용할 수 있다”고 강조했다.

세이지메이커 점프스타트는 완전 관리형 머신러닝(ML) 플랫폼이다. 통상 특정 분야에 특화한 AI 모델을 구축하려면 관련 데이터 학습 과정이 필수다. 이에 시스템통합(SI) 기업을 통해 파인튜닝 작업을 의뢰하거나 프라이빗 거대언어모델(LLM) 기업을 통해 자신만의 생성AI 모델을 구축하는 게 현재의 모습이다.
세이지메이커 점프스타트는 개발 지식만 있다면 직접 데이터를 머신러닝해 AI를 학습시킬 수 있다. 일례로 어떤 이미지 생성AI를 만들고 싶다고 하면 관련 이미지 여러개를 AWS의 스토리지 서비스인 S3에 넣어놓고, 다시 원하는 특징을 세이지메이커 점프스타트를 통해 학습시켜 자신만의 생성AI 모델을 만드는 형태다.

메타의 ‘라마(LLaMa)’를 비롯해 코히어(Cohere)의 ‘커맨드(Command)’, AI랩스의 ‘주라식(Jurassic)’, 스태빌리티AI의 ‘스테이블디퓨전(StableDiffusion)’ 등 거대언어모델(LLM)과 이미지 생성AI 등 점프스타트 플랫폼 안에서 다양한 FM을 골라 머신러닝을 수행하고 생성AI 모델을 파인튜닝할 수 있다.
LG AI연구원의 ‘엑사원(Exaone)’과 업스테이지의 ‘솔라(Solar)’등 국내 기업이 만든 FM도 활용할 수 있다. 인스턴스 선택과 인프라 구성 등 생성AI 모델에 필요한 다양한 옵션을 개발자가 조정할 수 있어 자유도가 높은 것이 특징이다.
박진우 아키텍트는 “데이터 준비부터 데이터베이스 구축, 학습, 모니터링을 모두 수행할 수 있다”며 “원하는 형태로 생성AI 모델을 만들어 배포할 수 있다”고 말했다.
하지만 세이지메이커 점프스타트의 기능을 십분 활용하려면 데이터 준비와 코딩 등 개발 지식이 있는 데이터 사이언티스트의 도움이 필요하다. 데이터를 촘촘하게 파인튜닝하고, 인프라 설정까지 만진 맞춤형 생성AI까지는 필요 없는 사용자라면 베드록이 안성맞춤이다.
베드록은 다양한 FM을 응용프로그래밍인터페이스(API) 방식으로 끌어와 바로 활용할 수 있도록 지원하는 플랫폼이다. 세이지메이커 점프스타트처럼 정교한 설정은 할 수 없지만 여러 FM을 한 곳에서 쉽게 선택할 수 있어 더욱 빠르게 생성AI 모델 적용이 가능하다.
AWS의 자체 FM인 타이탄을 비롯해 다양한 생성AI 모델을 한데 모았다. AWS가 FM의 업데이트와 관리를 지원하고 구동에 필요한 클라우드 인프라를 제공한다. 사용한 모델의 답변 정확도에 대한 평가 리포트를 제공하는 등 FM 활용과 관리에 도움을 주는 기능도 탑재했다.
사용자는 원하는 FM을 호출해 자신들의 서비스에 붙이기만 하면 된다. API 호출 형태라 일일이 여러 모델을 비교하고 골라 서비스에 물리는 것보다 편의성이 높다는 설명이다. 하나의 API로 여러개의 생성AI를 한 번에 물려 쓸 수 있기 때문에 여러 모델을 따로따로 시스템에 적용하는 것보다 공수가 적게 든다.
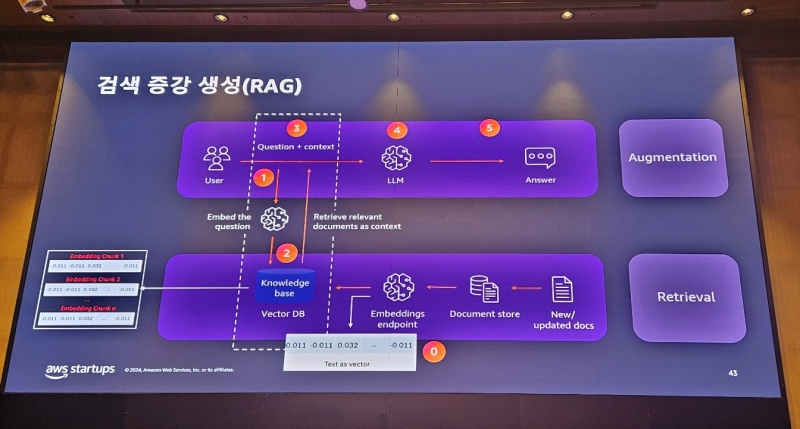
AWS는 검색증강생성(RAG) 기능을 접목해 환각 현상도 줄인다고 강조했다. RAG는 데이터를 숫자로 표현하는 벡터화를 통해 정확도를 높이는 게 핵심이다. 벡터 임베딩(Embedding). 즉, 벡터로 위치데이터를 만들어 거리가 가까울수록 관계성이 높은 것으로 판단한다.
데이터를 우선 벡터 임베딩해놓고, 관련 프롬프트 입력에 따라 벡터 데이터 간 거리를 계산한다. 여기에 파인튜닝을 거쳐 맥락까지 입력해 놓았다면 보다 정확한 답변을 얻을 수 있다는 설명이다.
김성민 AWS코리아 솔루션즈아키텍트는 “단어와 단어 사이의 의미 관계를 위치 데이터로 변환하고, 얼마나 가까이 위치했는지에 따라 의미 관계를 쉽게 파악할 수 있다”며 “벡터화를 통해 컴퓨터가 의미를 파악할 수 있도록 하는 게 RAG의 역할”이라고 강조했다.
글. 바이라인네트워크
<이진호 기자>jhlee26@byline.network