
진화하는 네이버의 OCR… “높은 인식률로 승부” [DEVIEW 2023]
네이버가 고도화한 광학문자인식(OCR) 기술을 소개했다. 기존 모델의 단점을 보완한 더 높은 인식률과 빠른 속도의 모델을 통해 자사 서비스의 편의성을 높인다는 계획이다.
27일 네이버는 서울 코엑스에서 개최한 ‘데뷰(DEVIEW 2023)’ 세션발표를 통해 새로운 OCR 기술 개발 이야기를 전했다. 이미지에서 텍스트 영역을 뽑아내 인식하는 OCR은 다양한 쓰임새로 더 많은 서비스에 적용되는 중이다.
네이버에 따르면, 이제까지 사용하는 클로바 OCR 모델은 이미지 검출과 이미지 인식을 각각 수행하는 ‘2스테이지(Stage)’ 방식이었다. 이미지에서 글자에 해당하는 영역을 ‘검출’하고 인식기가 글자를 ‘인식’하는 두 단계의 과정을 거치기 떄문에 2스테이지라는 이름이 붙었다.

이 모델도 문자 인식률이 낮은 건 아니었지만 이미지 검출기에서 글자 영역을 뽑아내는 ‘크롭 앤 리사이즈(Crop & Resize)’ 과정이 잘못되면 결과값도 잘못될 가능성이 있었다는 게 길태호 네이버클로바 엔지니어의 설명이다.
그는 “검출 실수가 일어날 경우 (인식하지 말아야 할) 인접한 텍스트까지 인식기가 인식하게 되는 문제가 있었다”고 설명했다. 예를 들어 참깨라는 단어가 담긴 이미지가 잘못 크롭될 경우 참끼로 인식하는 식이다. 인식기가 인식할 단어 자체가 제대로 잘리지 않아 결과값도 잘못 나오는 형태다.
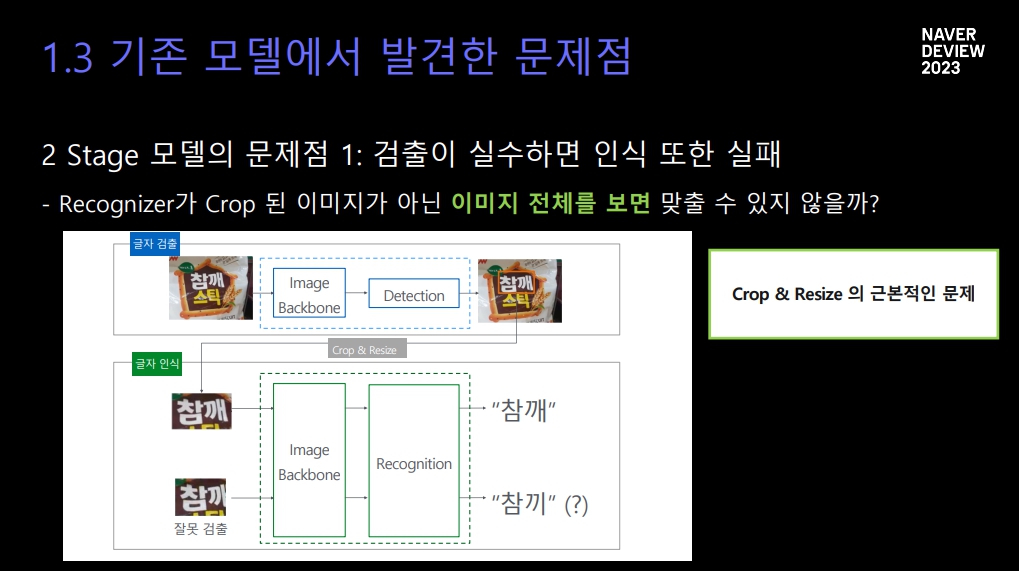
또 이미지에서 텍스트 영역을 발라낸 ‘이미지 백본(Backbone)’이 두 번 수행됨으로서 처리 속도에서도 손해를 봤고, 검출기를 업데이트해도 따로 인식기 학습과정이 필요해 유지보수가 힘든 경향이 있었다.
이에 네이버는 엔드투엔드 방법론을 쓴 ‘DEER(Detection-agnostic End-to-End Recognizer)’ 모델로 OCR 기술을 고도화했다. DEER는 검출과 인식을 하나의 모델로 합친 형태다. 하나의 이미지 백본을 검출과 인식단에서 공유함으로써 유지보수 편의성이 높고 속도도 빠르다.
특히 단어가 담긴 이미지의 특정 영역을 ‘짚는’ 방식으로 인식기가 작동하기 때문에 잘못된 이미지 크롭으로 인한 오인 우려가 적다. 또한 레퍼런스 포인트, 즉 단어를 인식하기 위한 중심점을 설정해 놓고 그에 대한 오프셋에 변화를 줘 글자를 인식하기 때문에 옆으로 돌아간 간판이나 뒤집힌 메뉴판 등 복잡한 이미지에서도 텍스트를 잘 뽑아낸다는 설명이다.
서석민 엔지니어는 DEER의 또 다른 장점에 대해 “(단어뿐 아니라) 줄과 문단 인식에 대한 니즈가 존재했다”면서 “로케이션 헤드를 추가해 단어 단위, 라인 단위, 문단 단위 인식 모두 수행할 수 있다”고 말했다. 그는 또 ‘유럽컴퓨터비전학술대회(ECCV) 2022’에서 주관한 챌린지에 참여해 DEER 모델의 성능을 검증받았다고도 강조했다.
앞으로 DEER 모델을 추가로 다듬어 더 가볍고 추론시간을 줄인 모델을 선보이는 게 네이버클로바의 계획이다. 새로운 DEER 모델은 오는 하반기 네이버 서비스에 적용될 예정이다.
글. 바이라인네트워크
<이진호 기자>jhlee26@byline.network