
CJ대한통운이 ‘택배 데이터’를 현장에 적용하는 방법
누가 그러더라. 데이터는 4차 산업혁명 시대의 석유라고. 클리셰처럼 느껴지는 이 명제가 맞는지 가타부타 따지지는 않겠다. 그만큼 ‘데이터’가 산업계가 공유하고 있는 중요한 의제인 것은 맞으니.
물류업계에서도 마찬가지다. 스스로를 ‘풀필먼트(Fulfillment)’ 기업이라 표현하는 많은 업체들이 ‘데이터’를 그들의 핵심 자산이라 이야기한다. 물류 영역에서 발생하고 있는 다양한 데이터를 기반으로 기업 운영 전략 고도화 및 고객 화주사 대상 서비스 강화에 활용할 수 있을 것이라고. 그렇다면 어떻게.
그 사례가 10월 30일 물류의 날 행사장에서 발표됐다. 경희정 CJ대한통운 TES물류기술연구소 부장은 “디지털 트랜스포메이션(Digital Transformation)의 기본요소는 데이터”라며 “데이터를 기반으로 인사이트를 도출하고, 그 인사이트가 현장과 시스템에 적용돼 다시 데이터로 축적되는 선순환을 만들어야 한다. 많은 이들이 이를 잘 알고 있지만 실행하기 힘든 부분이기도 하기에 더 강조하는 것”이라 말했다.

그렇다면 CJ대한통운은 어떤 데이터를, 어떤 방식으로 현장에서 활용하고 있을까. 코로나19 이후 가장 뜨거운 물류 비즈니스인 ‘택배’에서 발생하는 물동량, 상품, 지역 데이터를 중심으로 CJ대한통운이 어떻게 데이터를 수집, 분석하여 비즈니스에 적용했는지, 적용하고자 하는지 살펴본다.
물동량 데이터
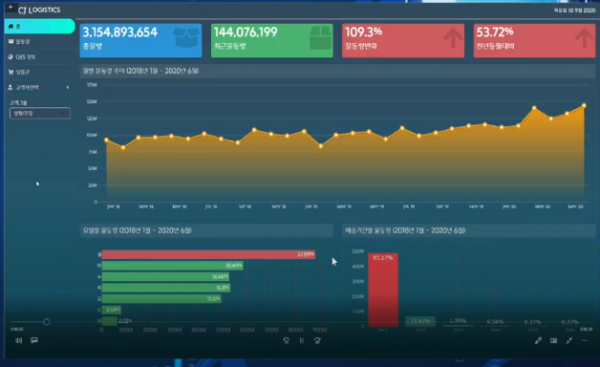
CJ대한통운은 하루하루의 택배 물동량 데이터를 수집한다. 여기서 물동량 데이터라고 하면 매일 발생하는 택배 물동량과 기간별 변화 추이다. 통상 택배 물동량은 이커머스의 성장과 함께 늘어나고 있지만, 항상 늘어나는 것은 아니다. 변폭이 있는데 CJ대한통운은 이 정보를 물동량 데이터를 수집하면서 함께 분석한다.
CJ대한통운은 그렇게 수집한 최근 3년치 데이터를 기반으로 ‘미래’의 물동량을 예측하는데 활용한다. 크게 단기, 중기, 장기로 나눠서 미래 물동량 데이터를 예측하는데 ‘단기 예측 물동량’은 택배 운영 효율 증대를 위해 활용한다. 예를 들어서 만약 다음주 물동량이 평소보다 많을 것으로 예상된다면 택배터미널의 운영인력을 더 많이 뽑아서 배치하던가, 더 많은 간선차량을 수급하는 데 활용할 수 있다는 설명이다.
중장기 물동량 예측 정보는 CJ대한통운의 월간 단위 운영계획을 수립하거나, 미래 신사업을 준비하는 데 활용한다. 예컨대 MFC(Micro Fulfillment Center)가 CJ대한통운이 데이터를 기반으로 준비하고 있는 신사업이다. 빠른 배송에 대한 니즈가 치고 오른다는 것은 업계의 공론이지만, 이를 실제 데이터로 수치화해서 근거자료로 활용하느냐, 아니냐는 그 느낌이 상당히 다르다.
물론 모든 수요예측은 ‘예측’이라는 말이 붙듯 틀릴 수밖에 없다. 최대한 틀리지 않게 현실 세계 수치의 근사치에 다가가도록 모델을 고도화해나가는 작업이 후행돼야 한다. 예컨대 코로나19는 시계열 택배 물동량 데이터로 쉽게 예측할 수 없는 변수였다. 실제 지난해 7월 말 기준 CJ대한통운의 택배 물동량 증가세는 꺾였는데, 올해는 오히려 물동량이 많아졌고 여기에는 코로나19로 인한 이커머스 물량 증가가 작용했다는 경 부장의 설명이다.
경 부장은 “코로나19로 인해서 택배 물동량이 엄청나게 증가했고, 이 수치를 예측 모델에 새로 반영했다”며 “예측 모델의 정확도가 떨어졌다면 그냥 떨어졌구나 생각하는 데 그치는 것이 아니라, 정확도가 떨어진 원인을 분석하고 그 결과를 새롭게 학습 요소로 반영하는 것이 중요하다”고 전했다.
상품 데이터
CJ대한통운은 물동량 데이터와 함께 택배 상품에서 발생하는 데이터를 수집한다. 상품 데이터를 추출하기 위한 기반 데이터는 택배 운송장에 기록되는 ‘품목명’이다. CJ대한통운은 이 품목명 데이터에 주요 이커머스 업체의 상품 카테고리 정보를 크로울링하여 결합, 학습 시켰다.
이를 통해 CJ대한통운은 송장 품목명을 대분류 10개, 중분류 119개, 소분류 512개까지 상품 카테고리로 매칭시킨 데이터를 보유하게 됐다. 예컨대 어떤 우유가 있다면 이 상품이 식품이고, 그 중에서도 가공식품, 그 중에서도 유가공식품이라는 것을 CJ대한통운은 식별할 수 있다는 뜻이다.
CJ대한통운은 상품 카테고리 데이터를 물동량 데이터와 결합하여 ‘트렌드’ 수집에 활용한다. 예를 들어서 영화 <기생충>이 상영되고 나서 짜파게티와 너구리 라면의 특정 지역 판매량이 늘었다는 결과를 예측이 아닌 ‘데이터’로 확보할 수 있게 된다는 뜻이다.
트렌드 정보는 CJ대한통운의 전략 의사 결정에도 활용되지만, 고객 화주사에게도 공유될 전망이다. CJ대한통운은 현재 상품과 출도착지 정보를 ‘대시보드화’ 해서 고객 화주사에게 트렌드 분석 서비스를 제공하기 위해 준비하고 있다. 고객사는 대시보드를 통해 ‘기간별’, ‘지역별’ 상품군별‘ 물동 흐름을 시군구 단위를 넘어 ’동‘까지 확인할 수 있다는 CJ대한통운 측 설명이다.
아울러, CJ대한통운은 택배 터미널에 설치한 장비를 통해 ‘박스’ 단위의 정보도 수집한다. ITS(Intelligent Terminal System)라 불리는 이 장비는 택배박스의 가로, 세로, 높이 세 변을 측정한다. CJ대한통운은 이 데이터를 기반으로 고객사의 택배단가를 측정하는데, 장비에 숨은 기능 중 하나가 ‘사진 촬영’이다. CJ대한통운은 기계를 통과하는 박스 사진을 촬영해 데이터화해서 보유하고 있다는 설명이다.
CJ대한통운은 수집한 데이터를 통해 특정 고객 화주사가 특정 상품에 이용하는 포장재가 ‘종이 박스’인지, ‘비닐’인지, ‘스티로폼 박스(EPS)’인지 확인할 수 있다. 향후 이 데이터를 라스트마일 배송까지의 ‘파손율’ 등의 데이터와 결합해서 어떤 포장재의 성능이 좋은지 인지하는 인사이트를 도출할 수 있을 것으로 CJ대한통운은 보고 있다.
지역 데이터
마지막 사례는 지도 데이터 수집 사례다. CJ대한통운은 택배기사의 할당 지역의 건물 유형이 학교인지, 아파트인지, 회사인지, 오피스텔인지 변수화했다. 만약 고층 건물이라면 해당 건물이 몇 층인지, 엘리베이터는 있는지 혹은 없는지도 데이터화했다는 설명이다. CJ대한통운은 이렇게 수집한 건물 유형 정보와 건물과 건물 사이의 거리, 밀집도, 차량의 진입 조건 등을 고려하여 모델을 만들었는데 그것이 ‘배송난이도 지수’다.
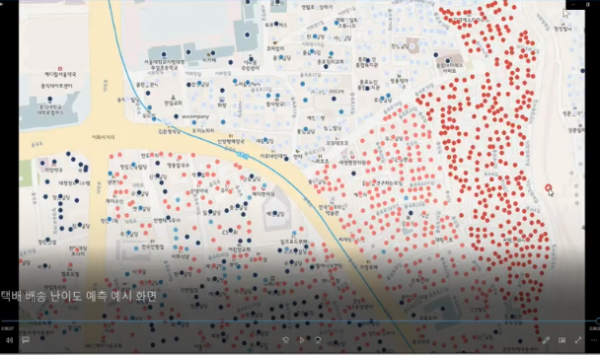
CJ대한통운은 배송난이도 지수를 기반으로 특정 지역의 배송 난이도를 ‘등급’으로 확인할 수 있다. 예를 들어서 계단과 좁은 골목이 많은 종로구 충신동은 배송 난이도 등급이 3등급으로 비교적 높다. 같은 아파트 단지더라도 인천 중구 흥신동은 엘리베이터가 있어서 1등급, 부산 해운대구 반여동은 엘리베이터가 없기 때문에 7등급을 받는다. 당연한 이야기지만 이 배송난이도 지수는 새로운 데이터가 축적되면서 앞으로 계속해서 바뀌어 나간다.
향후 CJ대한통운은 이 데이터를 택배기사 근로환경 개선에 활용한다는 설명이다. 예컨대 배송난이도 지수가 높은 지역에서 일을 하는 택배기사에게는 무동력 웨어러블 슈트를 도입하여 좀 더 편하게 일을 할 수 있도록 하는 등의 테스트를 수행한다는 계획이다.
경 부장은 “물류산업에서 디지털 트랜스포메이션은 데이터를 수집하고, 그 데이터로 인사이트를 도출하고, 의사결정에 반영해서 비즈니스에 적용하는 일련의 과정”이라며 “CJ대한통운이 많은 도전을 했지만, 중간에 시행착오도 많았다. 데이터로 미래를 보기 위해서는 몇 번의 실패를 하더라도 꾸준한 도전을 하는 것이 중요하다고 생각한다”고 강조했다.
글. 바이라인네트워크
<엄지용 기자> drake@byline.network
첫 댓글