
초당 7000만건 기록할 DBMS, 어디 없나요?
국내 한 반도체 회사의 경우, 공장의 전체 센서에서 발생하는 데이터가 1초에 700만 건이라고 한다. 1시간에 252억 건의 데이터가 발생하는 것이다. 그런데 이 반도체 회사는 현재 초당 1번씩 기록하는 방식에서 초당 10번 기록하는 방식으로 바꾸고 싶어한다. 더 정밀하게 기록해서 더 정밀한 예측 시스템을 만들고자 하는 것이다.
그러나 1초에 7000만건을 기록할 수 있는 데이터베이스관리시스템(DBMS)가 존재하지 않는다. 이 반도체 회사는 현재 오라클 엑사데이터에 데이터를 기록하고 있는데, 비용도 비용이지만 초당 생성되는 데이터가 10배 늘어나면 엑사데이터도 감당해내기 어려울 것으로 보고 있다.
이처럼 산업의 IoT 환경에서 쏟아지는 데이터는 DBMS 업계에게는 큰 숙제다. 그동안 경험하지 못했던 양의 데이터를 처리해야 하기 때문이다. 이에 기업들은 전통적인 관계형DB부터 NoSQL, 하둡, 스파크, 카푸카, 스플렁크, 엘라스틱 등 현존하는 모든 소프트웨어를 시험하고 있지만, 산업 IoT 환경의 폭발적 데이터량에 적합한 결과를 내는 소프트웨어를 찾지 못하고 있다.

최근에는 이런 문제를 해결하기 위한 대안으로 시계열 데이터베이스가 떠오르고 있다. 시계열 데이터란, 시간에 따라 기록되는 데이터를 말한다. 센서에서 발생하는 데이터를 주기적으로 기록한다면, 이런 것이 시계열 데이터다. 예를 들어 1분에 한 번씩 실내의 기온을 측정해서 기록한다면 시계열 데이터가 된다.
시계열 데이터는 오랫동안 존재했지만, 이를 처리하는 별도의 소프트웨어는 없었다. 대부분 관계형DB나 하둡 등 기존의 소프트웨어로 관리했다. 그러나 산업용 IoT 등 데이터가 폭증하면서 기존이 방식으로는 한계에 봉착했다.
시계열 DBMS는 이와 같은 시계열 데이터를 전문적으로 처리하기 위한 소프트웨어다. 센서에서 시간별로 쏟아지는 산업용 IoT 데이터를 처리하기 적합하기 때문에 주목을 받고 있다.
시계열 DBMS는 태그(센서)와 시간을 기준으로 인덱스를 구성하고, 데이터의 입력 속도가 빠른 것이 특징이다. 시간 단위로 데이터 통계를 보여주는 롤업 기능과 데이터 압축도 제공된다. 대신 관계형 DBMS처럼 트랜잭션을 보장할 필요는 없다. 데이터 변경 기능도 불필요하다.
아래 이미지는 DBMS의 순위를 매기는 사이트인 DB-ENGINES에서 지난 24개월 동안 DBMS에 대한 관심도 변화를 한눈에 표현한 그래프다. 시계열(Time Series) DBMS가 최상단에 있다.
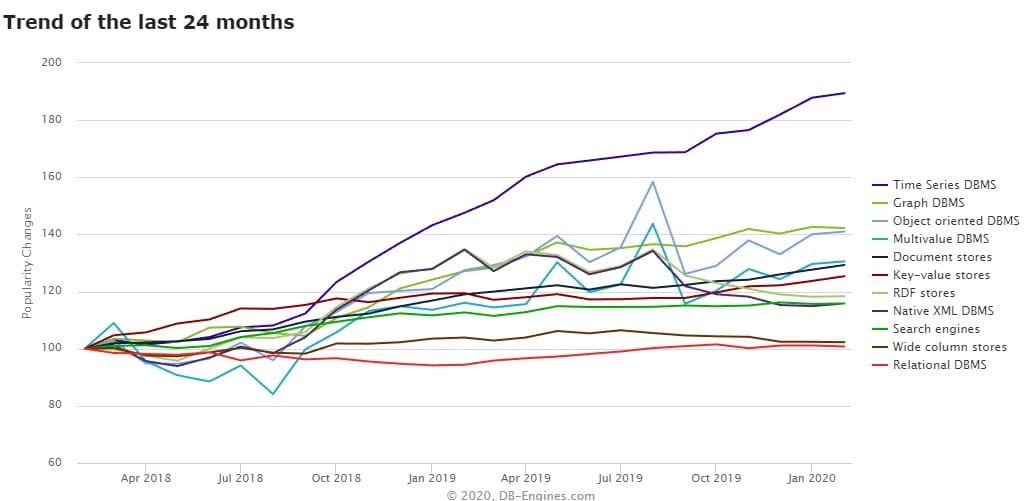
세계적으로 가장 유명한 시계열 DBMS는 InfluxDB(인플럭스DB)다. 이는 오픈소스 소프트웨어로 시계열 DBMS의 대표주자로 꼽힌다. 이 외에도 프로메테우스, Graphite, OpenTSDB 등의 오픈소스 기반의 시계열 DBMS가 있다. 상용 소프트웨어로는 Kdb+가 가장 유명하다.
국내에도 시계열 DBMS를 개발하는 스타트업이 있다. 알티베이스 CTO와 CEO를 역임한 김성진 대표가 지난 2013년 창업한 마크베이스(옛이름 인피니플럭스)가 주인공이다. 처음에는 로그 데이터를 관리하기 위해 마크베이스를 개발했는데, IoT의 발전으로 센서 데이터가 폭증하는 것을 보면서 시계열 DBMS로 제품의 포지셔닝을 바꿨다.
마크베이스는 지난 해 11월 세계성능평가기관(TPC) 사물인터넷(IoT) 벤치마크 ‘TPCx-IoT’ 성능테스트에서 세계 1위를 달성했다. TPC 웹사이트에 따르면, 이번 벤치마크 테스트에서 마크베이스는 초당 100만 건의 데이터를 기록했다. 마크베이스의 뒤를 레노보가 초당 74만 건으로 이었다.
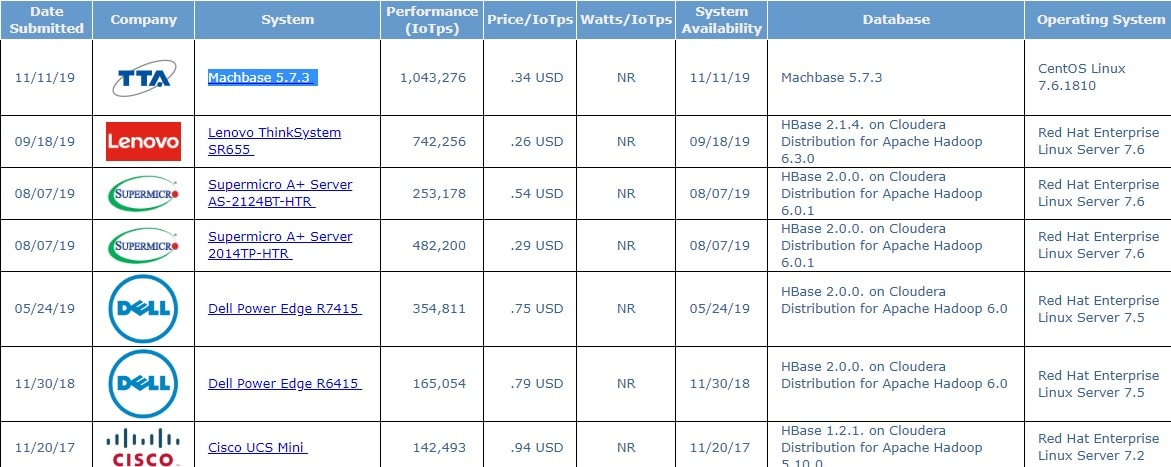
김 대표는 마크베이스가 세계 최고의 성능을 인정받았지만, 아직도 부족하다는 입장이다. 이 기사의 모두에 언급됐듯이 사업 IoT 현장에서는 훨씬 더 많은 데이터 처리를 요구하고 있기 때문이다. 마크베이스는 이와 같은 요구사항을 처리하기 위해 준비 중이다.
김 대표는 “산업 IoT 데이터를 처리하기 위해서는 시계열 DBMS 이외에는 답이 없다”면서 “마크베이스는 우리나라 스마트팩토리의 표준 DBMS가 되는 것이 목표”라고 말했다.
글. 바이라인네트워크
심재석 기자 <shimsky@byline.network>
첫 댓글