
구글이 전뇌화를 시도한다
사실 정확한 의미의 전뇌화는 아니다. 구글은 뇌 지도를 그리고 있다. 뇌 모양을 모델링하고 있는 것이 아니라, 감정이나 통각 등이 발생했을 때 전기신호가 어디로 어떻게 지나가는지를 밝혀내고 있다. 구글이 안드로이드 25 정도의 버전에서는 실제 안드로이드를 만드려고 하나보다.
해당 기사는 구글 AI 포럼에서 구글 리서치 사이언티스트 바이렌 자인(Viren Jain)의 발표를 요약한 것이다.

인간의 뇌는 일순간 100 엑사바이트 데이터를 만들어낸다
우선 세포 관찰은 전자현미경을 사용한다. 이를 통해 나노미터 단위의 해상도로 뇌 조직 3D 이미지를 생성한다. 그리고 이 이미지 데이터를 분석해 뇌 신경돌기를 추하고 시냅스가 어떻게 연결돼 있는지를 파악한다. 그런데 문제는 시냅스간 정보가 일자로 퍼지는 게 아니라 한꺼번에 여러 방향으로 퍼진다는 것이다. 따라서 데이터양이 엄청나다. 1입방밀리미터 조직당 1,000테라바이트 이상의 데이터가 생성된다. 뇌 전체에서는 100엑사바이트 수준의 데이터가 한꺼번에 움직인다. 만화 등에서 인간의 뇌는 칩 하나로 표현되는 경우가 많은데 실제로는 데이터센터 수준에 해당하는 것이다. 따라서 구글은 쥐나 금화조 등 작은 뇌를 가진 생물들을 먼저 분석한다.

연결체학(Connectomics)으로 파악하는 뇌 지도
이 부분은 어려우니 읽지 않아도 좋다. 가시덤불만 기억하자. 파악 방법은 일종의 딥 러닝이다. 그러나 한꺼번에 여러 가지의 딥 러닝을 시행한다. 커넥토믹스라고 부른다. 과정은 이렇다. 전자 현미경으로 뇌의 3D 이미지를 만든다. 경계 탐지기나 머신러닝 분류기로 이 이미지의 신경돌기 끝을 파악한 후, 워터쉐드와 같은 알고리즘을 사용해 이 시냅스가 어디에서 끝나는지를 파악하고 그룹화한다. 이것을 수억 번 반복하면 시냅스로 이어진 뇌 지도가 완성돼야 한다. 원리는 이렇지만 세포는 잘게 뻗어 나가는 가지가 많고 너무 작아 실질적으로 현재 공학 수준에서는 파악할 수 없다. 만약 한 가지가 파악되면, 이것이 실제로 한 가지가 맞는지를 추적한다. 동화에나 나올법한 앞이 보이지 않는 가시덤불 사이에서 가시덤불 줄기를 끝과 끝을 찾아내는 셈이다. 이 가시덤불 찾기 과정을 플러드 필링 네트워크(Flood-Filling Networks)라고 한다.
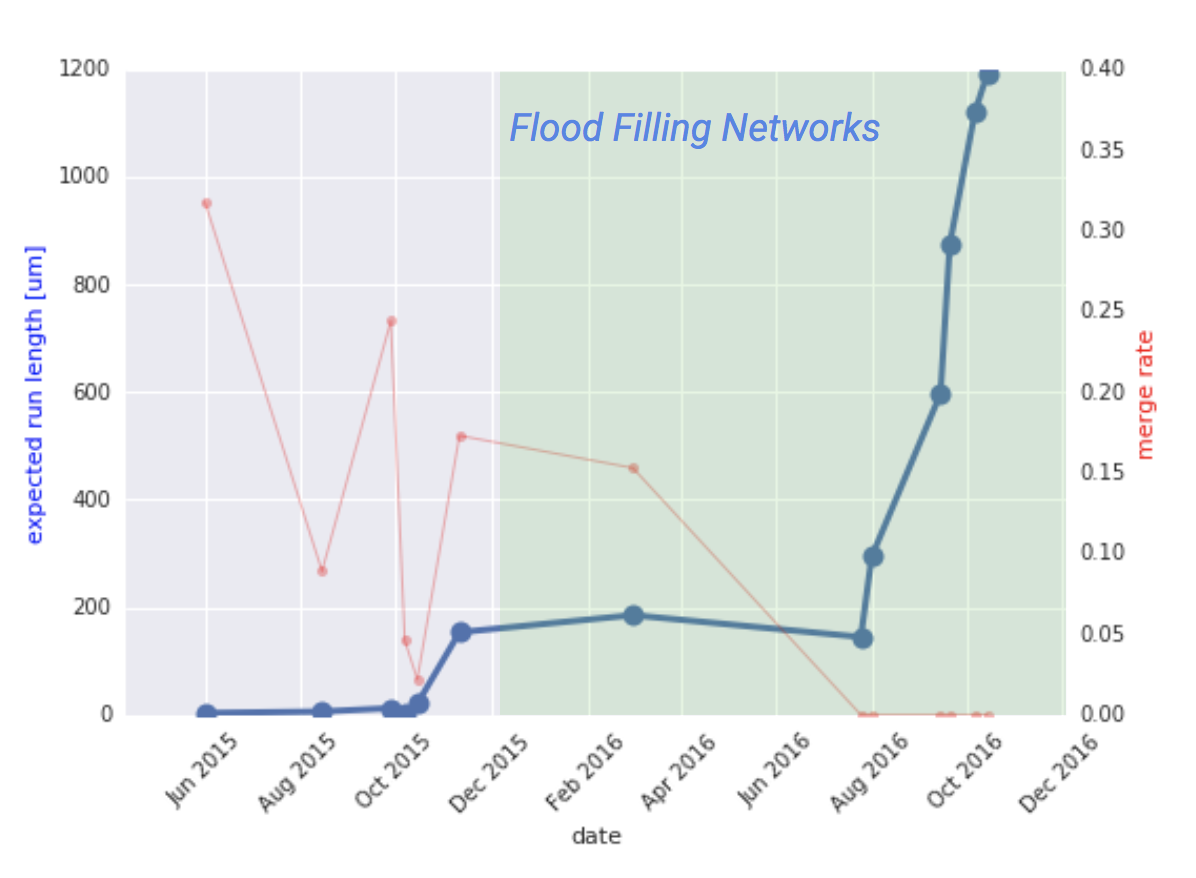
실수할 시점을 파악하는 알고리즘
이 과정 역시 물론 순탄치 않다. 가시덤불보다 더 미세한 조각들이 마구 뒤엉켜있는 것이 뇌의 형태기 때문이다. 따라서 구글은 막스 플랑크 연구소와 함께 예상 실행 길이(ERL)라는 메트릭을 개발했다. 줄기의 끝에서 따라가다가 혹시 줄기를 놓칠 때까지 얼마나 길게 따라갈 수 있느냐는 것을 예측하는 모델이다. 그러니까 1나노미터를 넘었을 때 줄기 찾기를 실패한다면 1나노미터까지의 추적만을 데이터로 반영하는 것이다. 이를 마구 반복하면 조금씩 줄기가 선명해지기 시작한다. 그렇다. 딥러닝이다.
ERL이 실수를 밝혀가는 과정을 2D로 치환하면 이런 모습이 된다 via GIPHY
실제로 뇌는 3차원의 것이므로 하나만 뽑아서 관찰하면 이런 모양이다 via GIPHY
지도를 완성해도 뇌는 만들어낼 수 없다
이 ERL을 도입한 방식으로 금화조의 뇌를 파악해보니 훨씬 우수한 성과를 만들어낸다는 것을 알 수 있었다. 플러드 필링에 ERL을 도입한 방법으로 구글은 금화조 뇌 일부를 파악했다.
그래서 금화조 뇌를 복제해 사이버 금화조를 만들어 아담처럼 아이돌 데뷔를 시켰으면 좋았겠지만 아직까지 그 수준에는 도달하지 못했다. 딥 러닝 기술이 매년 10배씩 발전해도 5~6년은 걸려야 될까 말까 한 수준이다. 그런데 5~6년이면 할 수 있다는 말로도 들린다.
그러나 뇌를 복제해도 사이버 뇌는 못 만든다. 예를 들어 뇌 구조가 단순한 지렁이 등의 뇌 지도를 완성했다고 해도, 지렁이에 이식해 조종하는 뇌는 만들지 못한다. 이유는 뇌를 시뮬레이션하는 것과 뇌 지도를 그리는 것은 반대의 방법으로, 시뮬레이션은 훨씬 더 어려운 작업이며 현실 세계의 데이터 러닝으로는 불가능에 가깝기 때문이다. 알파고가 바둑을 보는 것보다 바둑을 실제로 두는 데 더 오랜 시간이 걸린다고 생각하면 된다.
금화조의 뇌 지도를 일부 그려보면 이러한 모습이 된다. 각 컬러는 각 시냅스의 처음과 끝을 의미한다
구글은 대체 뇌를 왜 파악하나
그런데 구글은 대체 뇌를 왜 파악하려는 걸까. 우선 구글은 알츠하이머 등의 뇌 질환의 이유를 밝혀내려고 한다. 또한, 뇌 영상 등을 딥 러닝해 뇌에 문제가 있음을 판별해 의사들에게 제공하는 것도 목표로 하고 있다. 만약 전기신호를 빼곡히 파악한다면 인공 눈이나 귀 등 인공신체 제작에도 가속이 붙을 것이다. 공익적인 이야기다. 그런데 뇌 구조를 파악해 허를 찌르는 개인화 광고를 하거나, 실제로 뇌를 만들려고 한다는 말은 하지 않았다. 원래 기업 소속 과학자들은 다들 아니라고 한다. 인공지능 발표 미디어 행사에서 꼭 나오는 말이 인공지능이 사람 일자리를 뺏지 않는다는 말이다. 그러니까 너무 믿지 말자. 우리가 믿지 않는 동안 구글이 우리가 왜 안 믿는지도 파악해버릴지 모른다.
글. 바이라인네트워크
<이종철 기자> jude@byline.network