
[그게 뭔가요] 꿈만 꿨던, 답변엔진의 시대는 올 것인가
“핫이슈를 왜 뜨거운 감자라고 말할까?”
“산타는 왜 빨간 옷을 입을까?”
월드컵 열기로 뜨겁던 2002년, 네이버는 위와 같은 카피로 대대적인 TV 광고를 진행했다. 당시 네이버는 ‘지식검색’이라는 서비스를 막 내놓은 참이었다. 궁금한 것이 있으면 네이버에서 찾아보라는 메시지였다.

검색엔진의 한계
하지만 광고 내용과 달리 당시 네이버 검색은 이런 질문에 직접 답을 내놓지 못했다. ‘핫이슈를 왜 뜨거운 감자라고 말할까?’라는 질문을 입력하면 ‘핫이슈’ ‘뜨거운’ ‘감자’ 등의 단어가 포함된 문서를 찾아서 보여줄 뿐 이용자의 질문에 직접 답을 주지는 않았다.
이는 구글도 마찬가지다. 현재 구글에서 “핫이슈를 왜 뜨거운 감자라고 말할까?”라고 검색을 하면 ‘지식인 광고로 뜬 네이버, 포털 1위로 올라서다’라는 블로그 포스트가 1순위로 검색된다. 이 포스트에 ‘핫이슈’ ‘뜨거운’ ‘감자’라는 단어가 모두 포함돼 있기 때문이다.
검색엔진은 본질적으로 검색어가 포함된 문서를 찾아서 랭킹 순으로 보여주는 역할을 한다. 질문 의도와 관계없는 문서라도 검색어가 포함돼 있다면 먼저 노출될 수 있다. 때문에 검색엔진 이용자는 검색결과에서 자신에게 맞는 정보가 담긴 문서를 찾는 수고를 해야 한다. 검색 결과에 만족할 만한 답을 얻지 못해 이런 저런 다른 검색어를 넣어보는 경험을 안 해본 사람은 없을 것이다.
시맨틱 웹과 시맨틱 검색
이용자의 질문에 즉각 답을 내놓는 시스템에 대한 필요성은 오래전부터 제기돼 왔다. 하지만 컴퓨터는 검색어나 웹문서의 ‘의미’를 알지 못한다. 의미를 알아야 적절한 답을 내놓을 수 있는데 컴퓨터가 인간 언어의 의미를 파악하도록 만드는 것은 사실상 불가능한 일이었다.
컴퓨터가 인간처럼 ‘의미’를 이해할 수 있도록 만들고자 하는 여러 시도가 있었다. 가장 대표적인 것이 시맨틱 웹과 시맨틱 검색이다. 인간이 가진 지식체계를 ‘온톨로지’라는 거대한 데이터베이스로 만들고, 의미를 기반으로 정보를 색인하고 검색하려는 시도였다. 한때 네이트가 ‘시맨틱 검색’이라는 키워드를 앞세워 검색엔진 시장을 공략하기도 했었다.
하지만 인간의 지식을 컴퓨터가 이해할 수 있는 방식의 데이터셋으로 만든다는 것은 사실상 불가능한 일이었다. 학계에서 특정 분야에 대한 온톨로지를 구축하려는 시도가 있었지만, 일상 생활이나 비즈니스에 사용할 수 있는 수준의 서비스는 존재하지 않았고, 존재할 수 있다고 생각하는 이도 드물었다.
온톨로지는 필요없다
하지만 딥러닝과 생성형 AI가 이 같은 패배의식(?)을 퇴치했다. 컴퓨터가 인간의 지식체계를 이해할 수 있도록 온톨로지와 같은 시스템을 만들지 않았는데도, 생성형 AI는 그와 유사한 결과를 만들어주기 때문이다.
사람이 사용하는 단어를 벡터 임베딩(단어와 문장, 기타 데이터를 의미와 관계를 포착하는 숫자로 변환하는 방법)하면 서로 관련 있는 단어가 비슷한 벡터 공간에 위치하게 된다. 과거에는 인간이 한땀한땀 온톨로지라는 걸 만들려고 했었는데, 벡터 임베딩이 등장한 이후 이와 같은 과정 없이 단어와 단어 사이에 상관관계가 만들어진다. 예를 들어 노란색, 길쭉한 모양, 과일 등의 단어 벡터값을 계산하면 바나나라는 단어가 등장할 수 있게 된 것이다.
답변엔진의 시대
생성형 AI가 등장한 이후 검색엔진의 한계를 뛰어넘을 수 있다는 희망이 생겼다. 컴퓨터가 직접 인간의 질문에 답을 할 수 있게 된 것이다. 생성형 AI 기반으로 검색엔진 서비스를 제공하는 ‘퍼플렉시티’라는 회사는 이를 ‘답변엔진(Answer engine)’이라고 명명했다.
답변엔진은 사용자의 질문에 대해 직접적이고 상세한 답변을 제공하는 시스템이다. 기존의 검색 엔진과 달리 사용자가 입력한 질문의 맥락을 찾고 온라인에서 관련 정보를 종합해 즉각적으로 답변을 생성한다.
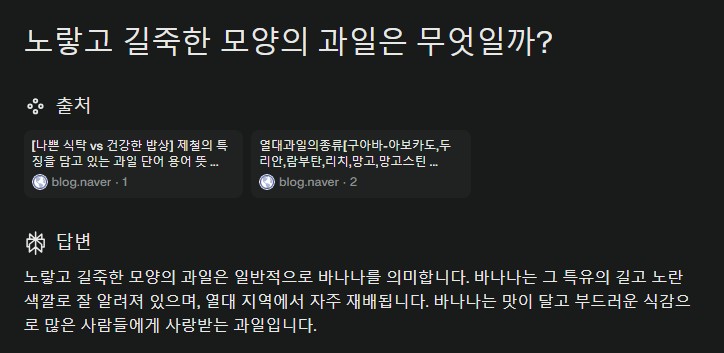
예를 들어 네이버나 구글에 ‘노랗고 길쭉한 모양의 과일은 무엇일까?’라는 질문을 던지면 제대로 된 답을 얻을 수 없다. 네이버와 구글 모두 전혀 엉뚱한 검색결과를 보여준다. 하지만 이 질문을 퍼플렉시티에 던지면 ‘바나나’라는 답을 내놓는다. 온톨로지와 같은 지식 데이터셋이 없이도 단어와 단어사이의 상관관계를 계산해 답을 찾아낸 것이다.
할루시네이션과의 전쟁
답변엔진은 기본적으로 LLM 기반의 생성 AI에 근간을 두고 있다. 챗GPT와 같은 서비스도 크게 보면 답변엔진이라고 할 수 있다. 하지만 생성 AI는 할루시네이션(환각)이라는 한계를 가지고 있다.
답변엔진이 내놓는 답에 틀린 정보가 담겨 있다면 활용도는 낮아진다. 답변엔진이 내놓은 답이 맞는지 틀린지 다시 사람이 검증해야 하기 때문이다. 자칫 답변엔진의 틀린 정보를 비즈니스 등에 적용할 경우 막대한 피해를 입을 수도 있다.
답변엔진은 이 때문에 ‘출처’라는 기능을 주로 이용한다. 관련 정보가 생성된 토대가 되는 웹페이지나 데이터를 출처로 보여준다. 이용자는 그 출처가 신뢰할만한 곳인지를 보면 답변엔진의 답을 그대로 받아들일지 의심해볼지 판단할 수 있다.
하지만 출처를 표기한다고 답변엔진의 답을 100% 신뢰하기 어렵고, 할루시네이션은 여전히 존재하기 때문에 이용자의 주의는 요구된다.
모 답변엔진에 “노랗고 길쭉한 모양의 과일은 무엇일까?”라는 질문을 던지면 ‘대추 방울토마토’라는 답이 나오기도 한다.
답변엔진의 종류
국내외에 다양한 답변엔진이 이미 존재한다. 네이버나 구글, 빙과 같은 검색엔진도 답변엔진으로 진화하기 위해 노력중이고, 새로운 스타트업도 다수 등장했다.
‘이용자가 원하는 정보를 찾아서 제공하는 서비스’는 인터넷 산업에서 가장 수익성이 큰 분야다. 구글과 네이버는 검색으로 인터넷 시장을 평정했다. 이제 검색엔진를 넘어 답변엔진 시장을 잡는 이가 차세대 네이버, 구글이 될 수 있을 것으로 보인다. 많은 스타트업이 이 분야에 뛰어드는 이유다. 물론 네이버와 구글도 자신이 이미 평정한 시장에서의 주도권을 잃지 않기 위해 노력을 하고 있다.
대표적인 답변엔진 서비스는 아래와 같다.
퍼플렉시티는 오픈AI 출신 엔지니어가 설립한 스타트업이다. 답변엔진이라는 용어를 만들어낸 대표적인 답변엔진 회사다. 최근 SK텔레콤과 제휴를 맺었다. SKT 이용자는 무료로 이용할 수 있다.
오픈AI가 구글 대항마로 내세우는 답변엔진이다. 챗GPT를 기반으로 질문에 대한 정보를 요약하고 관련 링크를 제공한다.
네이버가 만든 답변엔진이다. 하이퍼클로바 등 네이버의 자체 LLM을 기반으로 하고 있다.
빙 챗(코파일럿)
마이크로소프트 빙 검색이 AI를 탑재한 답변엔진이다.
국내 스타트업 라이너의 답변엔진. GPT, 클로드, 제미나이, Llama 등 다양한 LLM을 기반으로 답변을 생성한다.
국내 검색 솔루션 업체 솔트룩스의 답변엔진 서비스다.
국내 AI 스타트업 뤼튼의 서비스. 글쓰기 도우미 서비스로 시작한 뤼튼은 답변엔진으로 진화했다.
세일즈포스 출신이 설립한 AI 스타트업이다. 신뢰할만한 답변엔진으로 구글을 넘어서겠다는 포부를 밝히고 있다.
다양한 인공지능 모델을 통합한 올인원 AI 비서 서비스를 표방한다.
브라우저 확장 방식의 AI 서비스다.
하나의 질문에 대해 여러 AI 봇으로부터 받을 수 있는 AI 서비스다.
개발자를 위해 설계된 AI 기반의 대화형 검색 엔진이다.
글. 바이라인네트워크
<심재석 기자>shimsky@byline.network