
“음식 DB 표준화부터…비전AI 푸드테크 열린다”
식약처 DB 등 있지만 절대량 적어…표준화 중요
카카오헬스케어 “정밀 영양 푸드테크로 갈 것”
미국 농무부, 음식 분류만 395만개로 세분화
학습 데이터 품질 떨어지면 AI 훈련모델 성능 저하
KT, ‘음식 인식’서 다양한 연구…”섭취량 잘 추정하면 혁신”
코엑스(사장 이동기)가 오는 25일까지 코엑스 A,B,D홀에서 식품종합전시회 ‘2023 코엑스 푸드위크(제18회 서울국제식품산업전, Coex Food Week 2023)’를 개최한다. 지난 22일, 부대 행사로 제1회 월드 푸드테크 컨퍼런스가 열렸다. 푸드테크란 식품(food)과 기술(technology)의 합성어로 식품산업의 부가가치를 창출하는 기술을 일컫는다.
카카오헬스케어와 KT 등이 발표에 나선 컨퍼런스에선 솔루션 출시 전 기술 이슈 등을 공유하며 시장 개화기에 접어든 푸드테크의 현주소를 짚었다.


카카오헬스케어는 혈당관리서비스 출시를 준비 중이다. 당초 3분기 출시를 예정했으나, 본격적인 서비스는 내년에 이뤄질 예정이다. 이용자는 연속혈당측정기(CGM)와 스마트폰을 활용해 지속적인 혈당 관리를 받을 수 있다. 음식 섭취와 혈당의 연관성을 찾아내 개인별 맞춤 서비스 완성도 목표한다. 데이터 확보가 중요하다. 김준환 카카오헬스케어 이사가 발표에 나섰다.
“어떤 음식을 먹느냐에 따라서 혈당이 올라가는 형태나 모양이 다 다릅니다. 똑같은 음식을 먹어도 나와 내 친구가 다르고 다양한 모습이 있기 때문에 데이터의 표준화와 데이터의 수집이 앞으로 관건이 될 것 같습니다. 미국 사람 다르고 한국 사람이 다르고 각각 다른 형태의 CGM 데이터들이 나오게 되고, 우리나라에 맞는 데이터를 AI로 활용해야 합니다. 중요한 건 결국 푸드테크에선 음식 DB(데이터베이스)를 표준화하는 것들이 필요합니다. 저희가 공산품의 DB나 식약처의 DB를 활용하는데, 그 DB만 가지고는 양이 적기 때문에 DB가 잘 표준화가 돼야 비전AI를 통한 푸드테크 영역에서도 접근할 수 있습니다.”
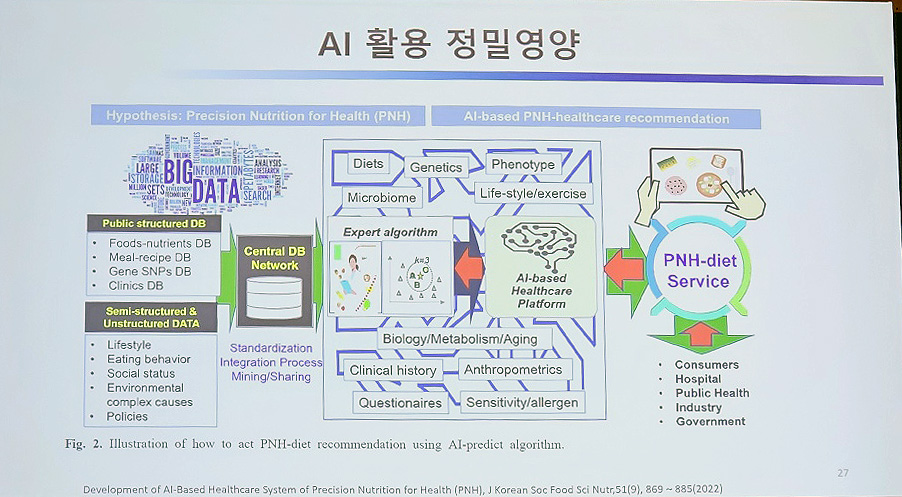
“결국 푸드테크는 ‘정밀 영양’으로 갈 수밖에 없는데요. 이 정밀 영양이라는 것은 DB 외에도 다양한 유전체 기술과 마이크로 바이오 기술 등 융복합 기술들이 총출동해야 결국 개인 맞춤형 정밀 영양으로 갈 수 있을 것이라 보고 있습니다. 카카오헬스케어에서 하나의 플랫폼에 데이터를 모으고 추천해드리면서 이런 형태로 접근하려고 합니다.”
권오상 서울대 푸드테크학과 교수는 행사 진행을 맡아 “디지털 헬스케어, 정밀 영양 등 개념들이 명확하게 정립된 것은 아니”라며 “새로운 산업이기 때문에 함께 만들어가는 과정이 필요하다”고 첨언했다. 또 “디지털 헬스케어의 핵심은 일상생활 데이터를 관리해서 예방의학 측면에서 접근하는 것이고, 푸드테크에서 정밀 영양과 결합이 된다면 환자가 아니라 일반 국민들에게도 활용할 수 있을 것”이라고 기대감을 보였다.

KT는 비전 AI 기반의 ‘음식 인식’을 연구 중이다. 해당 분야 이슈는 음식 DB가 너무 많다는 것이다. 국내 식약처에선 9만개로 음식을 분류했다. 미국 농무부는 무려 395만개로 음식 분류를 세분화했다. 천왕성 KT 융합기술원 비전AI 총괄 담당이 발표했다.
“음식 종류가 많다는 게 굉장한 허들입니다. 학습할 데이터가 많다보면 많이 라벨링이 돼야 합니다. 어마어마한 비용이 드는데, 요즘엔 라벨링이 없는 몇억장의 데이터를 학습을 하고, 표현력을 높인 다음에 라벨링된 데이터를 조금만 써 더 많은 음식을 커버하는 기법들이 많이 쓰입니다. 음식 간 상관관계 정보도 이용합니다. 김빠진 콜라와 커피가 비슷한데, 이런 것들을 잘 못 잡아내는 경우가 있습니다. 사진에서 옆에 있는 음식이 뭐냐에 따라 콜라일 것 같은데 그렇게 상관관계 정보를 이용합니다.”
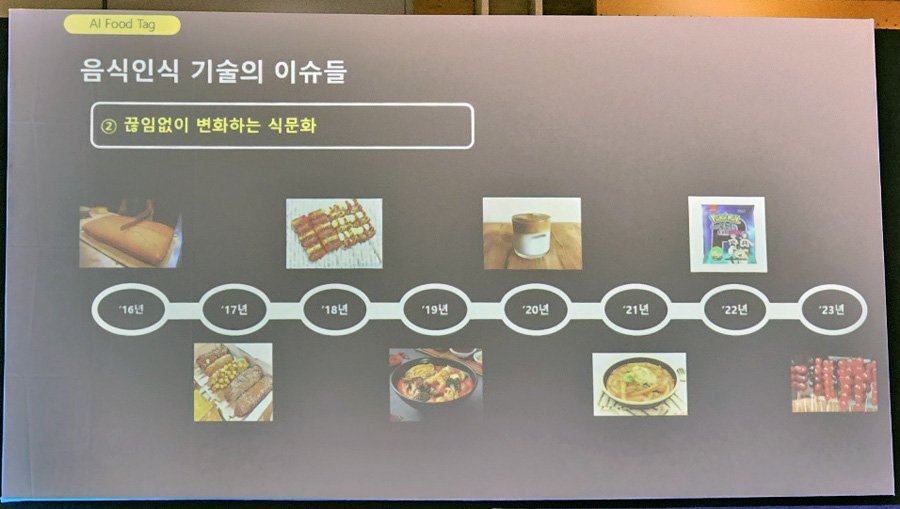
“(다른 이슈로는) 음식이 계속 나온다는 겁니다. 2016년에 대형 카스텔라가 나왔고, 17년에 명랑핫도그가 나왔습니다. 소떡소떡, 마라탕, 달고나커피, 로제떡볶이, 포켓몬빵 그리고 굉장히 이슈가 되고 있는 탕후루 등 이렇게 음식이 계속 나오니까 음식 인식 엔진은 이걸 다 계속 따라가줘야 합니다. 따라잡지 않으면 체감 정확도가 낮은 거죠.”
“학습 데이터 품질 문제도 있습니다. 보통 AI 쪽에서 데이터가 많으면 좋다 얘기를 하는데 특징을 알기 어려운 경우나 다른 음식이랑 굉장히 헷갈리는 경우에는 오히려 잘 훈련된 모델의 성능을 떨어뜨리는 경우가 많이 있더라고요. 그래서 정제하는 게 굉장히 힘들다고 얘기를 합니다.”
“섭취량 이슈도 있습니다. 먹은 양을 어떻게 맞추세요 이런 얘기도 하는데 솔직히 못 맞춥니다. 식약처에서 DB를 해줘서 된장찌개는 평균 1회 제공량이 200g입니다 라고 해서 200g에 대한 양 정보를 알려주고 그걸 활용하는데 그것도 사실 정확한 건 아니죠. 된장찌개가 메인 요리로 나온 경우랑 식판에 국 한접시로 나온 경우랑 다릅니다. 섭취량 측정을 위해 뎁스 센서를 써서 식사 전후 이미지의 높이 차이 그 다음 면적 차이를 계산하긴 하는데, 당연히 한계는 있습니다. 이걸 잘 추정할 수 있는 기술을 개발한다 그러면 굉장히 음식 인식 쪽에서 혁신이 되지 않을까 생각합니다.”
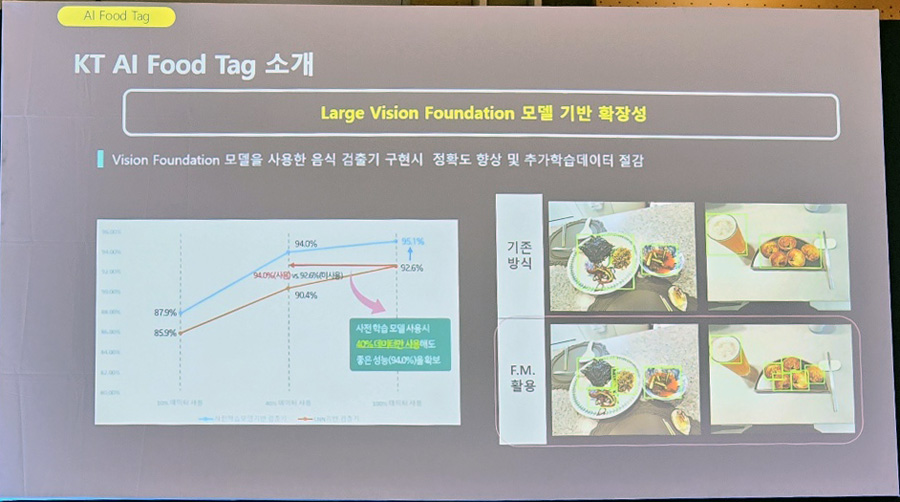
현재 KT는 대용량 비전 파운데이션 모델 기반으로 새 음식이 나올 때마다 소량의 데이터로 기능 확장을 추진하고 있다. 기존 대비 라벨 데이터량을 60% 절감했다. 더 적은 라벨 데이터로 정확도를 끌어올릴 수 있다는 것이다.
“내부 테스트를 해봤습니다. 파운데이션 모델을 안 썼을 때 92.6% 정확도가 (쓴 이후) 95.1%까지 올랐고, 데이터를 40%만 써도 94% 정도까지 거의 비슷한 수준의 성능을 냈습니다. 김치볶음밥, 떡볶이 같은 (비슷해 보이는) 애매한 음식들도 잘 못 맞추는 경우가 있었는데 자세하게 잘 맞추는 것도 확인할 수 있었습니다.”
글. 바이라인네트워크
<이대호 기자>ldhdd@byline.network