구글 ‘PaLM’, 최고 성능·최대 크기 초거대 AI 등극

구글이 기존 모델 성능을 훨씬 능가하는 초거대 인공지능(AI) PaLM을 최근 공개했다. PaLM의 규모는 기존 대표적인 초거대 AI인 오픈 AI의 GPT-3보다 약 3배 큰 5400억개 파라미터다. 기존에 가장 큰 모델이었던 마이크로소프트(MS)의 메가트론 튜링 NLG(Megatron-Turing NLG)보다 조금 더 큰 수준이다. 하지만 성능에 있어서는 현존하는 모든 초거대 AI를 훨씬 앞선다는 주장이다.
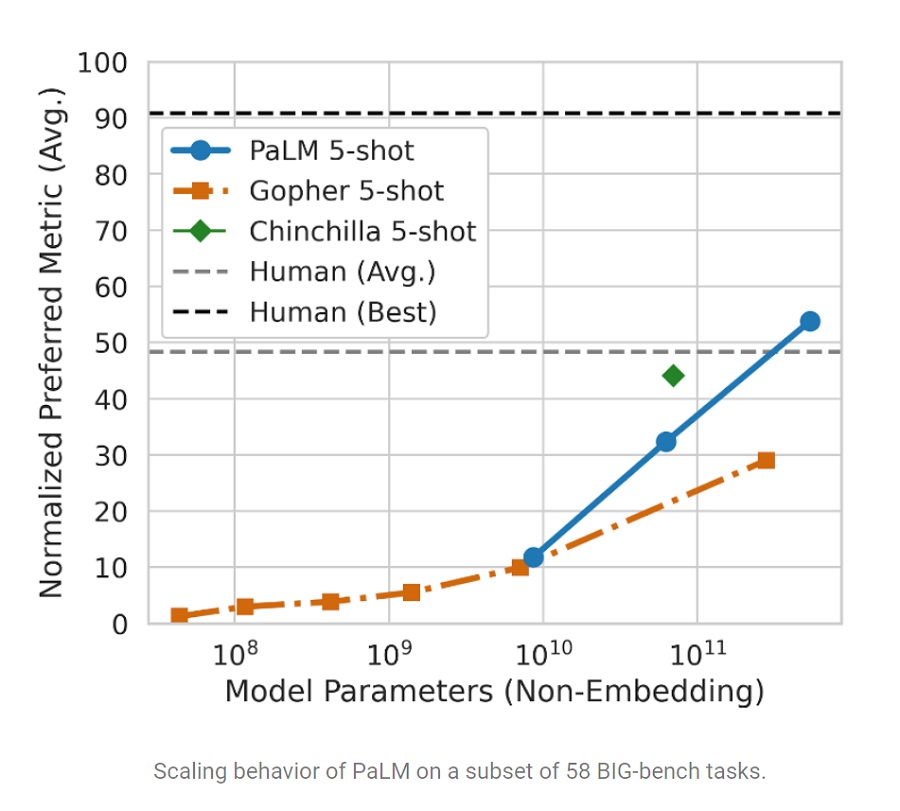
특히 AI 뿐만 아니라 사람 평균 수준도 능가해 주목받고 있다. 최근 개발된 벤치마크인 BIG-bench에서 PaLM은 인간 평균 수준을 능가하는 성과를 보였다. 보다 고도화된 과제인 산술 문제에서도 인간에 이전보다 근접하는 성과를 냈다. 초등학교 수준 수학 문제로 이뤄진 GSM8K 벤치마크에서는 9~12세 어린이가 풀 수 있는 문제의 60%를 풀었다.
PaLM은 ‘Pathways Language Model’의 약어다. 패스웨이(Pathways)는 작년 구글이 발표한 단일 모델로 매우 효율적이면서 도메인과 작업 전반에 걸쳐 일반화할 수 있는 것이 특징이다. PaLM은 이 패스웨이 시스템으로 훈련된 5400억개 매개변수를 지닌 고밀도 디코더(decoder) 전용 트랜스포머(transformer) 모델이다.

구글에 따르면 PaLM은 영어와 다국어가 섞인 데이터셋으로 사전 학습을 했다. 책, 위키피디아, 대화, 깃허브 코드 등이 포함해 질 높은 자료로 AI 학습을 진행했다는 주장이다. 특히 구글은 PaLM을 위해 무손실(lossless) 어휘집을 만들었다. 코드를 위해 모든 공백을 보존하고 어휘에 없는 유니코드 문자들을 바이트(bite) 단위로 분할했다. 숫자에 대해서는 각 자릿수에 대해 하나씩 고유한 토큰(token)으로 나눴다.
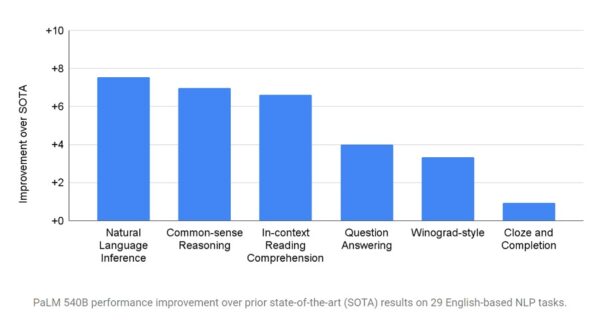
연구팀은 이렇게 만들어진 PaLM의 성능을 다른 여러 초거대 AI와 비교했고 대다수 과제에서 기존 모델을 훨씬 능가하는 것을 확인했다. 연구팀은 공식 블로그에서 “우리는 널리 사용되는 29개의 영어 자연어처리(NLP) 과제를 활용해 PaLM을 평가했다. PaLM은 29개 과제 중 28개에서 GLaM, GPT-3, 메가트론 튜링 NLG, 고퍼(Gopher), 친칠라(Chinchilla), 람다(LaMDA)를 능가했다”고 말했다.
150개의 새로운 언어 모델링 과제로 이뤄진 최신 벤치마크인 BIG-bench(Beyond the Imitation Game Benchmark)에서는 AI 모델은 물론 인간 평균을 능가했다. 구글 연구팀은 “PaLM은 같은 과제를 풀어달라고 요청한 사람들의 평균 점수보다 좋은 성과를 보였다”고 말했다.
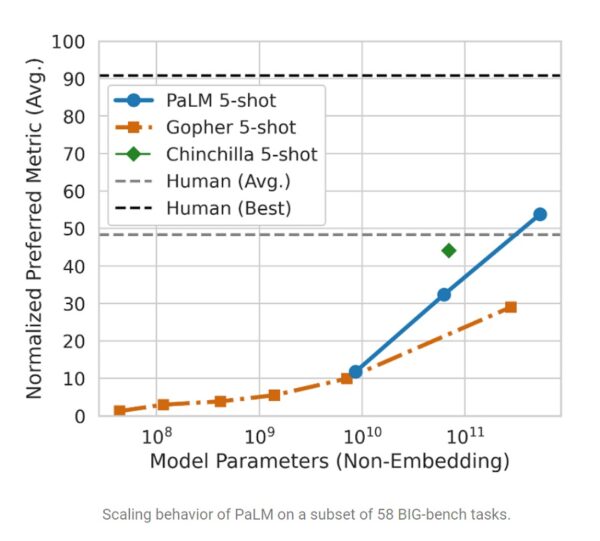
더불어 “PaLM은 여러 개의 BIG-bench 과제에서 인상적인 자연어 이해와 생성 능력을 보였다. 예를 들어, 원인과 결과를 구분하거나 개념적으로 복합된 것을 적절한 맥락 안에서 이해하거나 이모지에서 영화를 맞추는 것까지 해냈다”고 강조했다.

보다 복잡한 과제인 산술 영역에서도 기존 AI 모델을 넘어서고 인간에 근접하는 점수를 냈다. 구글에 따르면 PaLM은 초등학교 수준 수학문제로 구성된 GSM8K 벤치마크에서 58% 문제를 풀었다. 기존 모델 최고 점수는 GPT-3의 55%였다. 해당 점수를 내기 위해 GPT-3는 7500개 문제로 이뤄진 학습세트로 파인튜닝하고 외부 계산기, 검증기와 결합했다.
연구팀은 “PaLM으로 인한 새로운 점수는 질문 세트의 대상인 9~12세 어린이가 풀 수 있는 문제의 평균 60%에 근접하기 때문에 특히 흥미롭다”고 말했다.
PaLM이 이러한 성과를 낼 수 있는 비결로는 생각의 연결 고리 프롬프팅(chain-of-thought prompting)을 모델 규모와 결합한 것을 꼽았다. 고퍼와 같은 기존 초거대 AI 모델에서는 해당 과제에서 규모에 비해 성능을 내지 못했다는 설명이다.
학습한 데이터셋의 22%만이 영어가 아닌 다국어임에도 불구하고 번역을 포함한 다국어 NLP 벤치마크에서도 우수한 성능을 보였다는 주장이다.
코딩 과제에 대해서도 우수한 성적을 보였는데 사전 학습 데이터셋의 5%만이 코드임을 고려하면 놀라운 결과다. 자연어로부터 코드를 생성하는 것, 여러 언어 간 코드를 번역하는 것, 컴파일 실수를 해결하는 것 등 여러 코딩 과제에 대해 PaLM은 우수한 성능을 보였다.
연구팀은 “AI 학습에 50배 적은 파이썬(Python) 코드를 사용함에도 불구하고 미세 조정(fine tuning)된 코덱스(Codex) 모델과 동등한 결과를 보여 특히 주목할 만하다. 이러한 결과는 더 큰 모델이 다른 프로그래밍 언어와 자연어 데이터로부터 학습을 더 잘 전달하기 때문에 큰 모델이 작은 모델보다 효율적일 수 있다는 기존 주장을 강화한다”고 전했다.
글. 바이라인네트워크
박성은 기자<sage@byline.network>