
구글 클라우드, 데이터 호수와 창고를 통합했다
기업이 데이터를 분석하기 위해서는 빅데이터를 모아두는 곳이 필요하다. 각 시스템에서 발생하는 데이터를 하나의 통에 담아둬야 필요할 때 데이터를 꺼내 분석할 수 있다.
이를 위한 대표적인 기술로는 데이터웨어하우스(이하 DW)와 데이터레이크가 있다. 두 기술 모두 빅데이터를 저장하는 용도로 사용되지만, 근본적인 차이도 있다. DW는 주로 구조화 된 형태로 데이터를 저장하며 관계형 데이터베이스를 기반으로 하고 있어 표준 SQL로 데이터에 접근할 수 있다. 반면 데이터레이크는 방대한 원시데이터를 저장하는 용도로 주로 활용되며, 구조화 여부에 관계없이 담긴다. DW가 월별실적과 같은 전통적인 리포팅에 주로 이용된다면, 데이터레이크는 머신러닝 및 AI 등 새로운 분석을 위한 데이터 플랫폼이라고 할 수 있다.
DW와 데이터레이크는 양자택일 해야하는 기술이 아니다. 대부분의 기업에는 수많은 형식의 데이터가 혼재해 있고, 다양한 방식의 분석이 필요하다. 이 때문에 DW와 데이터레이크 모두 필요한 존재였다. 두 개의 통해 데이터를 담아 놓고 필요에 따라 데이터를 옮겨서 분석하는 경우가 많다. 하지만 이렇게 되면 투자가 중복되고, 데이터 이동 과정에서 보안문제이나 데이터 유실 등의 우려가 생긴다.

이 때문에 최근에는 DW와 데이터레이크를 통합하려는 시도가 잇달아 등장하고 있다. 전통적인 DW 기술업체들은 데이터레이크를 기존 솔루션에 통합하려는 노력을 하고, 데이터레이크로 시작한 기업들도 SQL 분석 환경을 마련하고 있다.
관련기사 : [이솔소] 무한확장 가능한 분석 플랫폼 ‘그린플럼’
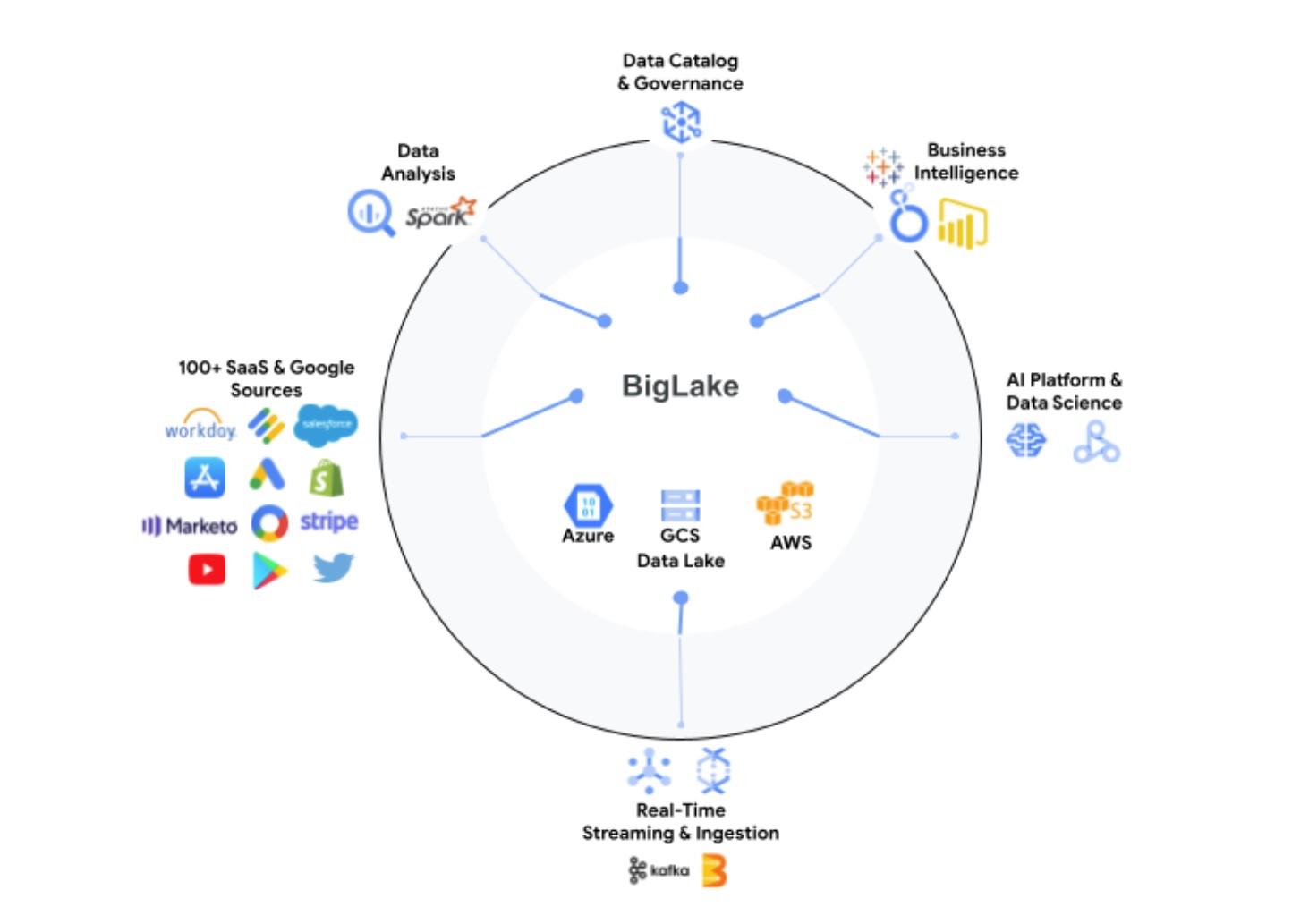
최근 구글 클라우드가 발표한 ‘빅레이크(Big Lake)’는 이같은 요구에 대한 구글이 내놓은 해법이다. 구글 클라우드 측에 따르면, 빅레이크는 데이터레이크와 DW를 통합한 스토리지 엔진이라고 정의된다. 구글 클라우드의 DW 서비스인 ‘빅쿼리’를 데이터레이크인 ‘구글 클라우드 스토리지’로 확장해 유연한 오픈 레이크 하우스 아키텍처를 구현하고 있다는 설명이다. 데이터레이크하우스는 데이터레이크를 위해 비즈니스인텔리전스, 머신러닝, 데이터 거버넌스 등의 데이터 관리 기능을 결합한 아키텍처다. 데이터레이크와 DW를 통합함으로써 데이터를 복제하거나 이동시킬 필요 없이 단일 데이터 플랫폼을 통해 데이터를 저장, 관리 및 분석할 수 있다는 점을 구글은 내세운다.
빅레이크는 아파치 스파크(Apache Spark)와 같은 오픈소스 데이터 처리 엔진을 비롯해, 구글 클라우드 서비스와 파케이(Parquet) 등 오픈파일 형식을 아우르는 API 인터페이스를 통해 세분화된 액세스 제어 역량을 갖출 수 있도록 지원한다.
구글 클라우드 측은 “트위터의 경우 빅쿼리와 함께 빅레이크의 스토리지 기능을 이용해 데이터 제한 없이 트위터 사용자의 플랫폼 사용 현황과 콘텐츠 선호도를 파악하고 있다. 그 결과, 초당 3백만 개 이상의 집계를 실행하는 광고 파이프라인을 통해 매일 수 조 건에 달하는 이벤트와 관련된 콘텐츠를 제공할 수 있게 되었다”고 설명했다.
빅레이크의 특징은 분석가들이 주로 사용하는 다양한 기존 분석엔진과 타사 클라우드 스토리지를 지원한다는 점이다. 예를 들어 아파치 스파크나 BI(Business Intellegence) 툴을 분석에 활용할 수 있고, AWS S3나 마이크로소프트 애저에 데이터가 있어도 구글 빅레이크로 데이터를 관리할 수 있다.
황경태 구글 클라우드 커스터머 엔지니어링 매니저는 “데이터레이크와 DW가 통합된 빅레이크는 스토리지나 시스템에 구애 받지 않고 분석할 수 있다”면서 “이제 데이터를 복제하거나 이동시킬 필요가 없다”고 설명했다. 이어 그는 “빅레이크는 구글 클라우드 전략의 핵심으로 모든 툴이 통합된다”고 강조했다.
글. 바이라인네트워크
<심재석 기자>shimsky@byline.network