
AI 사대천왕 앤드류 응, GTC 2022서 데이터 중심 AI 강조
인공지능(AI) 분야 사대천왕 중 하나로 불리는 앤드류 응(Andrew Ng) 교수가 데이터 중심 AI(Data-centric AI) 중요성을 강조하고 나섰다. 모델 크기를 늘리기보다는 AI를 적용하는 도메인 내 데이터 질을 높일 필요가 있다는 주장이다.
앤드류 응 박사는 21일부터 24일까지 온라인으로 개최되는 엔비디아 GTC 2022에서 데이터 중심 접근 방식에 대해 소개했다. AI 분야에서 가장 저명한 인물 중 한 명인 그는 LandingAI와 DeepLearning.AI의 창립자이자 코세라(Coursera)의 공동 회장이자 공동 창립자이며 스탠퍼드대 겸임 교수다. 과거에 그는 바이두(Baidu)의 수석 과학자이자 구글 브레인 프로젝트의 설립자였다.
응 박사는 AI 개발에 있어 모델보다 데이터가 더 중요한 시점에 도달했다고 말한다. 모델에 대해 계속해서 미미한 개선을 하기보다 모델을 미세 조정하기 위해 품질 좋은 데이터에 초점을 맞추면서 모델을 상대적으로 고정된 상태로 유지하는 것이 합리적이라는 주장이다.

그는 “데이터 중심 AI는 빅데이터에서 좋은 데이터로의 전환이다. 특히 AI 민주화를 위해 중요하다”고 강조했다.
AI 시스템은 코드와 데이터로 구성된다. 전통적인 AI 개발 방식에서는 추가 작업이 필요할 때 코드를 조정한다면, 데이터 중심 AI에서는 데이터에 대해 작업한다. AI 시스템을 만들기 위해 시스템적으로 데이터를 엔지니어링하는 것이라고 할 수 있다.
보다 많은 산업 분야에 AI 확산이 이뤄지지 못하는 이유로 앤드류 응 교수는 먼저 작은 규모 데이터셋을 꼽았다. 그는 “컨퍼런스에서 제조업 관계자들에게 검출하기 원하는 결함이 있는 대상에 대한 이미지를 얼마나 가지고 있냐고 물었더니 50개 이하가 50%를 넘었다”고 말했다.
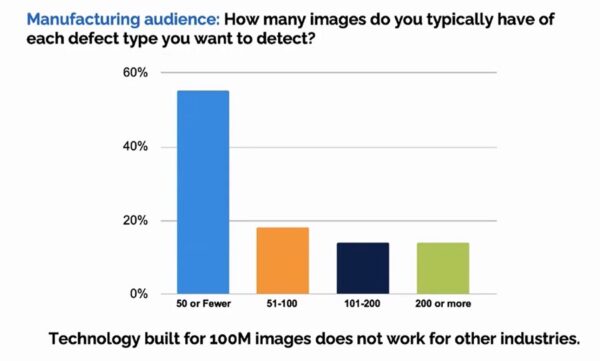
제조 분야에서는 주로 결함이 있는 제품을 식별하는 작업을 하는데 좋은 생산 라인에는 결함이 있는 제품 이미지가 많지 않은 것. 응 박사는 이것이 전문가가 데이터 엔지니어링을 통해 지식을 문서화할 수 있도록 권한을 부여해야 하는 이유라고 주장한다.
산업 현장에 AI를 적용하기 힘든 두 번째 이유는 중요도가 떨어지지만 필요한 롱테일(long tail) 주제가 있다는 것이다. 앤드류 응 박사는 “광고, 웹검색, 추천 시스템과 같이 가치가 큰 것으로 여기지는 주제가 있다. 반면 다른 산업군을 살펴보면 제조업에서는 알약을 검출해야 하고 스틸 제조자는 스틸을, 반도체 제조자는 와퍼(wafer)를 검출해야 한다. 각각에 대한 AI는 모두 따로 작동하기에 따로 만들어져야 한다”고 설명했다.
그러면서 “이것들에 대해 수직 플랫폼(vertical platform)을 만들어서 최종 사용자들에게 그들이 원하는 방식대로 AI를 맞춤화할 수 있게 해야 한다. 이 때 모델보다는 데이터를 엔지니어링해야 한다”고 말했다.
지도 학습에서 좋은 데이터셋이란 일관되고 정확한 라벨, 대표성이 있으면서 질이 높은 인풋값, 배치 후 변경값을 반영하는 것이다. 앤드류 응 박사는 “데이터 클리닝은 사전 과정에서 한 번 하는 작업이 아니다. 머신러닝 개발에서 순환하는 과정 중 하나가 되어야 한다. 어떤 데이터 부분이 개선돼야 하는지 인식해야 한다”고 강조했다.
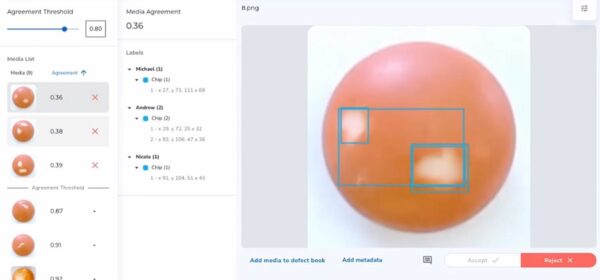
핵심은 일관성이다. 전문 지식은 단일하게 정의되지 않을 수 있다. 한 전문가에게는 결함으로 간주될 수 있는 것이 다른 전문가에게는 승인을 받을 수 있다. 필요한 것은 전문가가 동의하는 부분을 신속하게 파악할 수 있는 좋은 도구와 워크플로우가 필요하다는 것이 앤드류 응의 입장이다.
앤드류 응은 “합의가 되는 곳에 시간을 할애할 필요가 없다. 대신 전문가들이 동의하지 않는 부분에 초점을 맞춰 결함의 정의를 제시할 수 있어야 한다. 데이터 전체의 일관성은 AI 시스템이 좋은 성능을 빠르게 얻을 수 있도록 하는데 매우 중요하다”고 전했다.
글. 바이라인네트워크
박성은 기자<sage@byline.network>