
데이터 창고(DW)는 잊어라…데이터 호수를 맞이하라
전통적인 엔터프라이즈 IT 환경에서 ‘분석’이라는 것을 하기 위해서는 데이터웨어하우스(DW)라는 시스템이 필요했다. 데이터 창고(Data Warehouse)라는 이름에서 알 수 있듯 데이터를 저장해두는 것이 DW의 목적이다. 전사적자원관리(ERP) 고객관계관리(CRM) 공급망관리(SCM) 등 기업에서 활용되는 다양한 시스템에서 생성되는 데이터를 DW 에 담아두고, 분석이 필요할 때 이 창고의 데이터를 대상으로 분석을 하자는 접근이었다.
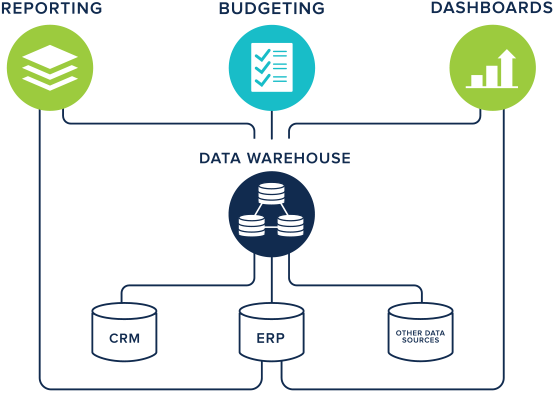
DW는 웬만한 기업 대부분 갖고 있었다. 비즈니스인텔리전트(BI)를 구현하기 위해서 DW는 필수적이었기 때문이다. 테라데이타, 사이베이스(현재 SAP에 피인수), 그린플럼(EMC에 피인수) 등은 DW를 위한 전용 데이터베이스관리시스템(DBMS)를 공급하면서 큰 성장을 이뤘다.
DW를 위한 DB는 관계형 데이터베이스(DB)다. ERP CRM SCM 등에서 생성되는 데이터가 구조적인 정형 데이터여서 관계형 DB가 효율적이었다. 마이크로스트레티지와 같은 DW용 분석 툴도 관계형 데이터베이스를 대상으로 하고 있다.

그러나 이제는 바야흐로 빅데이터 시대다. 데이터는 ERP CRM SCM 등의 데이터만 분석 대상이 아니다. 사물인터넷, 소셜미디어, VoC(Voice of Cumstmer), 웹사이트 클릭스트림 등 다양한 데이터가 분석 대상이 됐다. 기존에는 이런 데이터들은 생성돼도 버려지기 일쑤였지만, 4차 산업혁명이 이야기되는 현재는 이런 데이터에서 경쟁력이 생긴다. 인공지능이나 머신러닝 등을 활용하기 위해서도 이런 데이터는 중요하다.
이를 위해 등장한 개념이 ‘데이터 레이크’다. 데이터 레이크는 데이터의 종류를 묻지도 따지지도 말고 저장하는 공간을 말한다. 기업에서 발생하는 데이터를 모아서 한 곳에 저장해두자는 접근법은 DW와 같지만, 대상으로 하는 데이터의 종류가 다르다. DW는 구조적 정형 데이터가 대상이지만, 데이터 레이크는 모든 데이터가 대상이다.
그런데 모든 데이터를 저장한다는 것은 쉬운 일이 아니다. 데이터는 기하급수적으로 늘어가는데 기업 내 데이터센터는 한정적이다. 하둡 같은 기술이 등장하면서 빅데이터를 저장하는 것이 쉬워졌지만, 무한대로 하둡 노드를 늘릴 수도 없고 늘린다해도 분석이 쉽지 않다.
이 때문에 클라우드에 데이터 레이크를 구축하는 것이 유리하다. 클라우드는 데이터가 늘어나는 대로 빠르게 대응할 수 있기 때문이다.
 클라우드의 대표주자 AWS(Amazon Web Service)의 서비스를 사례로 어떻게 데이터 레이크를 구축할 수 있는지 살펴보자. 넷플릭스와 같은 회사가 AWS를 활용해 데이터 레이크를 구축해두고 있다고 한다.
클라우드의 대표주자 AWS(Amazon Web Service)의 서비스를 사례로 어떻게 데이터 레이크를 구축할 수 있는지 살펴보자. 넷플릭스와 같은 회사가 AWS를 활용해 데이터 레이크를 구축해두고 있다고 한다.
AWS가 자랑하는 데이터 레이크는 흔히 알고 있는 S3(Simple Storage Service) 다. S3는 AWS가 세상에 처음 내놓은 클라우드 서비스로, 데이터의 종류와 규모에 관계없이 담아둘 수 있다.
데이터 레이크의 특징은 원시 데이터(Raw Data)를 그대로 저장한다는 점이다. DW에 데이터를 담기 위해서는 데이터를 추출-변형-적재(ETL)이라는 과정을 거쳐야 했다. 구조가 다른 각기 다른 DB에서 나온 데이터이기 때문에 하나의 구조로 맞춰야 하기 때문이다.
그러나 데이터 레이크는 이런 ETL과 같은 중간 과정이 필요없다. 다양한 원시 데이터를 저장해두고 있다가 분석을 할 때 필요한 형태로 데이터를 가공한다. 데이터를 저장하는 시점이 아니라 분석하는 시점에 정의하는 것이다. 이때문에 즉시(ad-hoc) 분석이 가능하다.
대신 데이터 레이크에는 ‘카탈로그’라는 기능이 필요하다. 어떤 데이터가 어디에 저장돼 있는지 카탈로그를 만들어놓고, 분석이 필요할 때 그것을 보고 필요한 데이터가 있는 곳의 데이터에 접근하는 것이다. AWS는 글루(Glue)라는 이름의 카타로그 서비스를 제공한다.
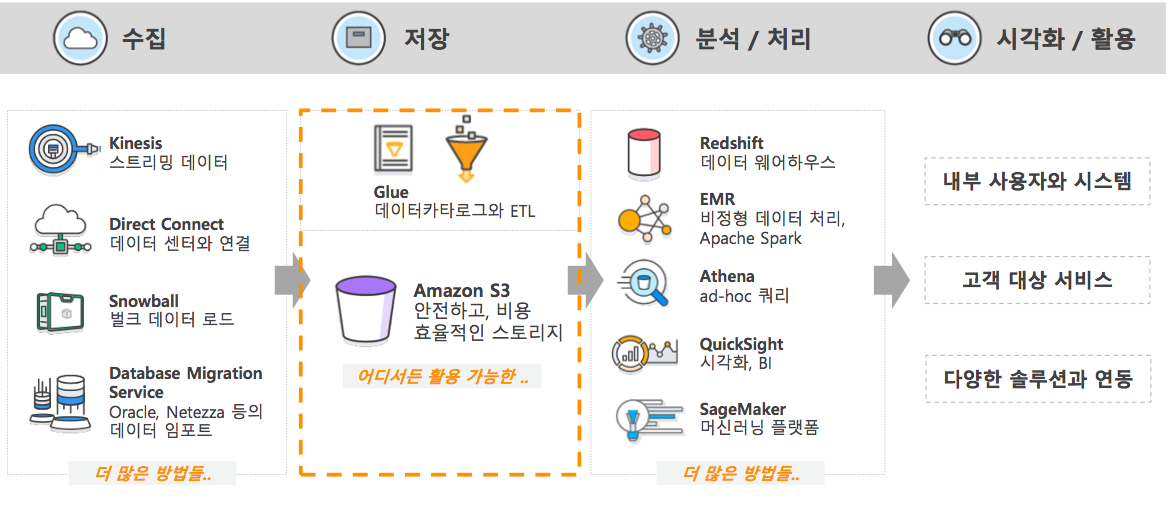 데이터 레이크에 저장된 데이터는 분석이 필요할 때 그에 맞는 방법으로 분석할 수 있다. 예를 들어 전통적인 BI 툴로 분석을 하고자 한다면 DW에 데이터를 보낼 수 있다. Glue는 카탈로그뿐 아니라 ETL 기능도 하는 서비스다. 데이터 레이크(S3)에 저장된 데이터를 Glue를 통해 DW으로 보낼 수 있다. AWS는 레드시프트라는 DW용 DB 서비스를 제공중이다.
데이터 레이크에 저장된 데이터는 분석이 필요할 때 그에 맞는 방법으로 분석할 수 있다. 예를 들어 전통적인 BI 툴로 분석을 하고자 한다면 DW에 데이터를 보낼 수 있다. Glue는 카탈로그뿐 아니라 ETL 기능도 하는 서비스다. 데이터 레이크(S3)에 저장된 데이터를 Glue를 통해 DW으로 보낼 수 있다. AWS는 레드시프트라는 DW용 DB 서비스를 제공중이다.
이뿐 아니라 하둡과 같은 비정형 데이터를 분석할 때는 EMR(Elastic MapReduce)이라는 서비스를 이용하면 되고, ad-hoc 쿼리는 안테나라는 서비스로 처리할 수 있다. 퀵사이트(QuickSight)라는 시각화 툴, 세이지메이커(SageMaker)라는 머신러닝 플랫폼으로도 분석할 수 있다.
앞에서 언급한 넷플릭스 이외에도 다양한 기업들이 AWS 기반의 데이터 레이크를 구축해 두고 있다. 미국 나스닥(Nasdaq)의 경우 아마존 S3에 모든 데이터를 저장해 두고, 레드시프트(DW)와 EMR 기반의 프레스토로 데이터를 분석한다. 나스닥은 데이터레이크로 마이그레이션 하는데 겨우 7맨먼쓰(Man/Month)만이 들었다고 한다.
AWS코리아 양승도 상무는 “데이터가 여러 장소에 분산돼 있으면 어떤 데이터가 원본 데이터인지 알수도 없고, 분석할 때 시간과 비용이 많이 들기 때문에 모든 데이터를 하나의 중앙 저장소에 저장해 놓고 분석하는 데이터 레이크가 필요하다”면서 “아마존 S3와 글루는 데이터 레이크를 구축하기에 가장 편리하고 효율적인 솔루션”이라고 말했다.
글. 바이라인네트워크
<심재석 기자> shimsky@byline.network