
60년 인공지능 역사에 가장 충격적인 기술 ‘딥러닝’
4차 산업혁명 시대의 기술 ④ 딥러닝
IT에 약간의 관심이라도 있는 분은 최근 ‘인공지능(AI)’에 대해 접할 기회가 많을 것입니다. 신문방송 등에서 쉽게 인공지능 이야기를 만날 수 있습니다. 인공지능으로 인해 우리의 삶이 얼마나 편리해질 것인지에서부터 인공지능 때문에 일자리가 사라질 것이라는 무서운 이야기도 들립니다.
요즘 들어 갑자기 인공지능 이야기가 많이 나오지만, 인공지능이라는 기술이 최근에 등장한 것은 아닙니다. 인공지능이 본격적으로 연구된 것은 1950년대부터입니다. 지금까지 인공지능 연구 역사는 두번의 전성기와 두 번의 암흑기가 있었다고 합니다. 현재는 세 번째 전성기를 맞고 있는 셈이죠.
존 매카시, 마빈 민스키 등 젊은 컴퓨터학자들이 다트머스에 모여 회의를 하면서 인공지능이라는 말을 만들었습니다. 그리고 인공지능은 가장 각광받는 분야로 떠올랐습니다. 이 시대(1950년 후반~1960년 초반)가 인공지능 1차 전성기입니다.


이 시기에는 추론과 탐색이라는 기법으로 인공지능을 시도했습니다. 이는 경우의 수를 계산하는 방식입니다. 정해진 룰(rule)에 따라 컴퓨터는 계산합니다.
그러나 사람이 모든 상황에 대한 룰을 만들 수 없기 때문에 이 방식은 실제로 쓸모있는 인공지능 제품이나 서비스를 만들지는 못했습니다. 간단한 문제는 풀수 있지만 진정한 인공지능이라고 부르기는 어렵습니다.
1차 전성기가 지나고 인공지능은 침체기에 빠집니다. 인공지능에 대한 기대는 엄청 컸는데 실제로 인공지능이 가치를 발휘하지 못했기 때문이죠.
그러다가 1980년대 후반, 1990년대 초반 다시 인공지능 붐이 일어납니다. 이때는 지식베이스라는 기법이 각광을 받습니다. 그리고 이 지식베이스는 전문가 시스템이라는 것으로 활용됩니다. 예를 들어 의학에 대한 지식베이스를 잘 구축하면, 컴퓨터가 의사처럼 진단과 처방을 내릴 수 있을 것이란 접근입니다.
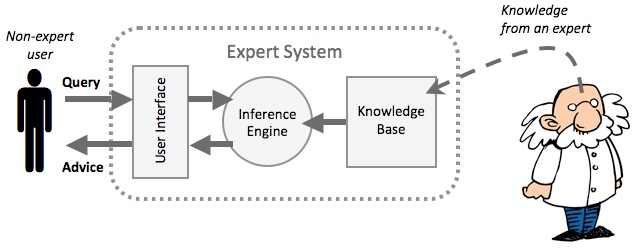
이 접근법의 문제는 지식베이스를 구축하기 어렵다는 점입니다. 지식 전문가가 직접 정해진 규칙에 따라 지식을 입력해야 할 뿐 아니라, 거의 모든 것을 다 미리 지식베이스화 해야 합니다. 예를 들어 사람 손 하나가 뭔지 컴퓨터에 알려주려고 해도 손은 팔의 끝에 달린 것, 손에는 손가락이 5개 달려있고, 손가락 끝에는 손톱이 달려있고, 손가락 마디는 엄지엔 두 개, 나머지엔 세개, 손바닥은 어떻고, 손등은 어떻고 손금은 어떻고, 주먹을 쥐면 어떻게 되고 손을 펴면 어떻게 되고 손에는 어떤 근육이 있고 핏줄은 어떻게 연결돼 있고 손이 연결된 팔이란 무엇이며 뭐 이런 식으로 일일이 다 정의해야 합니다.
그러다보면 지식베이스에는 수천만, 수억개 지식이 쌓이게 됩니다. 그러나 지식이 늘어나면 지식끼리 서로 모순되거나 일관되지 않는 문제가 생깁니다.
지식베이스는 어느 정도 성과를 거뒀습니다. 그러나 연구자들은 지식베이스를 만든다는 것이 사실상 불가능하다는 것을 깨닫게 됩니다. 부분적으로는 전문가 시스템 방식으로 사용 가능하지만, 기대에 부응하는 인공지능 시스템을 개발하지는 못합니다.
그리고 다시 인공지능 연구는 암흑기에 빠집니다.

그러던 2012년 어느날, 인공지능 연구자들을 깜짝 놀라게 하는 사건이 벌어집니다. 글로벌 이미지 인식 경진대회인 ILSVRC(Imagenet Large Scale Visual Recognition Challenge, 이하 이미지넷)에서 충격적인 사건이 벌어집니다. 이 대회에 처음 참가한 토론토 대학의 슈퍼비전이라는 팀이 그야말로 압도적인 승리를 거둔 사건입니다.
이 대회는 사진을 보고 컴퓨터가 그 사진이 무엇인지 맞히는 대회입니다. 사람은 이미지를 보면 직관적으로 고양이인지, 호랑이인지 알 수 있지만 컴퓨터는 이것이 엄청나게 어려운 일입니다.
2012년 이전까지 최고 우수한 인공지능 컴퓨터가 74% 정도의 정답률을 보였습니다. 세계 최고의 연구자들이 정답률 74% 선에서 0.1% 싸움을 하고 있었습니다. 75%로 가는 것이 모든 참가자들의 꿈이라고 해도 과언이 아니었습니다.
그런데 2012년 대회에서 슈퍼비전은 84%의 정답률을 보였습니다. 모두가 0.1%포인트 개선을 위해 사력을 다하고 있는데, 갑자기 10%포인트 개선된 인공지능이 등장한 것입니다. 모두가 충격에 빠진 것은 당연했죠.
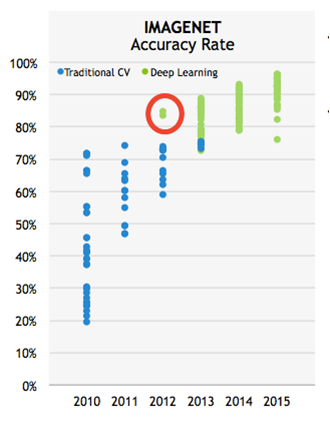
토론토 대학이 획기적인 정답률을 기록한 것은 ‘딥러닝’이라는 기술을 사용한 덕분입니다.
딥러닝 기술의 가장 큰 장점은 컴퓨터 스스로 이미지의 특징(또는 구별점)을 만들어 낸다는 것입니다. 이전까지는 사람이 이미지의 특징을 기술해야 했습니다. 그 전에도 기계학습은 있었지만, 어떤 특징을 학습하고 어떤 특징은 학습하지 말아야 하는지 사람이 정해줘야 했습니다.
예를 들어 고양이가 무엇인지 학습시키려고 하면 고양이의 특징을 사람이 기술해야 합니다. 이는 생각보다 어려운 일입니다. 사람이 어떤 기준으로 고양이라는 사물을 판단하는지 잘 모르기 때문입니다.
아이가 고양이라는 동물이 무엇인지 배울 때 엄마가 일일이 고양이의 특징을 일일이 설명주지 않습니다. 아이가 고양이를 보면 엄마는 “저게 고양이야”라고 알려줍니다. 아이가 고양이를 보고 “강아지다”라고 말하면 “아니야 저건 강아지가 아니라 고양이야”라고 말해줍니다. 이런 일이 반복되면 아이는 자연스럽게 고양이가 무엇인지 알게 됩니다.

이 방식을 통해 ‘알파고’가 이세돌 9단과 커제 9단을 꺾었습니다. 알파고는 바둑두는 법이 프로그래밍 돼 있지 않습니다. 딥러닝을 통해 스스로 승리하는 법(점수 올리는 법)을 깨달은 것입니다.
예를 들어 아이가 ‘벽돌깨기’라는 게임을 처음 해보게 된다고 가정합시다. 일일이 설명서를 보면서 게임을 배우지 않습니다. 아이가 아무렇게나 받침대를 움직이다 보면 공이 와서 맞고 튕겨서 벽돌을 깹니다. 이것이 반복되면서 아이는 ‘공을 받아내야 한다’는 게임의 규칙을 깨닫습니다. 또 게임을 반복하면서 어딘가 빈틈에 잘 넣으면 한 번에 많은 벽돌을 깨고 점수가 올라간다는 사실도 배웁니다. 알파고가 바로 이런 방식으로 바둑 두는 법을 배웠습니다.
딥러닝은 이처럼 스스로 고양이와 강아지를 구별하는 어떤 특징, 게임에서 점수가 올라가는 어떤 기법 등을 스스로 찾아냅니다. 이것이 딥러닝의 가장 큰 장점입니다.
스스로 사물의 특징을 만들어 학습하는 딥러닝은 인공지능 연구 역사에서 가장 획기적인 기술이 될 것입니다. 딥러닝 이전까지 50년 인공지능 역사가 실패했던 것은 사람이 컴퓨터에게 무언가를 하도록 일일이 정해주려고 했기 때문입니다.
하지만 이제 컴퓨터 스스로 구별하는 기준을 찾아냅니다. 고양이와 강아지의 차이를 컴퓨터 스스로 찾고, 바둑에서 좋은 수와 나쁜 수를 구별하는 기준을 스스로 찾습니다.
이 때문에 인공지능의 발전을 상상하기 힘듭니다. 사람이 정해주지 않은 특징을 스스로 찾아내기 때문에 훨씬 더 많은 발전을 이룰 수 있습니다.
최근 가트너가 2022년이면 의사와 변호사 등 전문직을 인공지능이 대신할 수 있을 것이라고 내다봤습니다. 바로 딥러닝의 힘입니다.
글. 바이라인네트워크
<심재석 기자>shimsky@byline.network