
NC AI, 개인-산업 현장서 쓸 강력한 멀티모달 모델 4종 공개
‘VARCO-VISION 2.0’ 멀티모달 모델 4종 공개
동급 비전언어모델서 앞선 성공 기록
4종 모두 연구용 오픈소스로 공개
NC AI가 16일 한국어 기반 멀티모달 AI 기술력을 집약한 VARCO-VISION 2.0, 총 4종(14B/1.7/1.7B OCR / Video-Embedding)의 멀티모달 AI 모델을 오픈소스로 공개한다고 발표했다.
이 중 VARCO-VISION 2.0 14B는 글로벌 오픈소스 VLM(비전언어모델) 최고 성능으로 알려진 InternVL3-14B(140억 파라미터)와 알리바바의 Ovis2-16B, Qwen2.5-VL 7B 등 동급 모델들을 영문 이미지 이해, 한국어 이미지 이해, OCR 벤치마크 등에서 능가하는 성과를 달성했다고 밝혔다. 4종의 모델 중 14B와 임베딩 모델 2종은 오늘(16일), 1.7B와 OCR모델은 차주 중 공개 예정이다.

14B 모델은 복잡한 멀티이미지 분석과 고도화된 추론이 필요한 업무용 환경에 최적화되어 있으며, 1.7B 경량 모델은 스마트폰이나 PC 등 개인 기기에서도 원활하게 동작할 수 있도록 설계됐다.
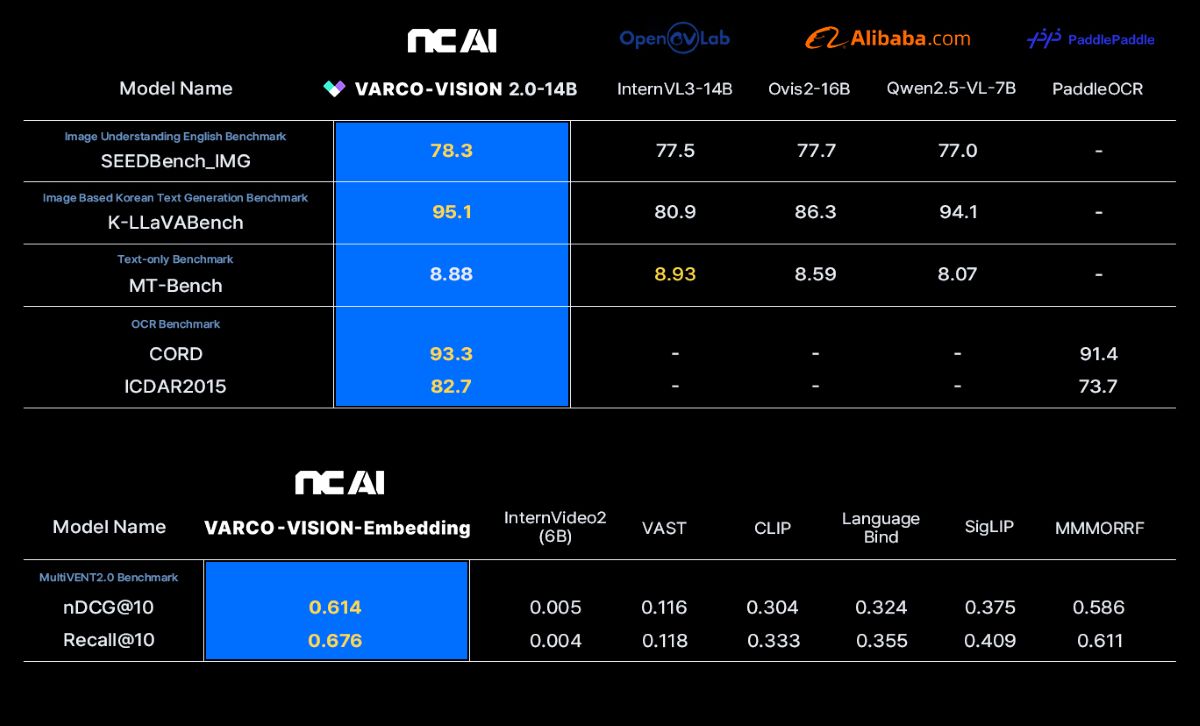
이미지 내 문자를 인식하는 광학 문자 인식 작업에 특화된 모델인 VARCO-VISION-1.7B-OCR도 내놓았다. 이 모델의 가장 큰 특징은 AnyRes 해상도 분할 입력 방식을 적용한 것으로, 입력 이미지를 다수의 조각으로 나누고 각 부분에서 높은 해상도 정보를 생성하는 구조를 통해 다양한 해상도의 이미지를 손실 없이 효율적으로 처리한다. 특히 노이즈나 흐림 등이 포함된 어려운 환경에서도 이미지의 전반적인 분위기나 시각적 단서를 바탕으로 정밀하게 글자를 인식할 수 있어, 한국어-영어 혼합 환경에서도 높은 인식 정확도를 보여준다는 게 회사 설명이다.
멀티모달 임베딩 모델 VARCO-VISION-Embedding은 텍스트, 이미지, 비디오 간의 의미적 유사도를 고차원 임베딩 공간에서 정밀하게 계산한다. 회사에 따르면 임베딩이란 영상의 내용을 숫자로 변환해서 저장하는 것으로, 이 기술을 통해 사용자의 자연어 질의에 따라 동영상 콘텐츠를 고차원 임베딩으로 변환하고, 이 임베딩 간의 거리나 유사도를 기반으로 관련성 높은 이미지나 비디오를 검색할 수 있다.
NC AI는 이 모델이 비디오 검색 벤치마크(MultiVENT2.0) 제로샷 기준 최고 성능 모델로 등극했다고 밝혔다. 이미 잘 만들어진 검색 AI의 능력을 복사해서 영상 검색 AI에 그 능력을 더해주는 방식을 적용, 기존 이미지-텍스트 검색에 특화된 고성능 모델의 가중치 차이를 계산해 도출한 벡터를 파인튜닝된 비디오-텍스트 모델에 덧셈 방식으로 적용해 추가 학습 없이도 검색 성능을 강화했다.
이번에 공개된 4종의 모델은 금융, 교육, 문화, 쇼핑, 제조 등 다양한 도메인에서 활용 가능하다. 복잡한 보고서, 계약서, 청구서 등의 자동 분석 및 디지털화, 표와 차트가 포함된 문서 처리나 주문서 자동 정리 및 요약 등 문서 처리 및 자동화 분야에서 광범위하게 활용할 수 있다.
NC AI는 이번에 공개하는 4종 모델 모두를 연구용 오픈소스로 공개한다고 밝혔다. 이번 멀티모달 AI 모델 4종 공개를 통해 국내 AI 기술의 글로벌 경쟁력을 입증하는 동시에 오픈소스 생태계를 통한 기술 민주화에도 기여, 정부가 추진하는 ‘소버린AI’ 강화에 힘을 더할 계획이다.
이연수 NC AI 대표는 “기술 고도화로 글로벌 트렌드가 텍스트만 처리하는 언어모델을 넘어 비전 모델을 함께 활용하는 비전언어모델로 전환되고 있다”며 “이번 4종 모델 공개를 통해 미디어와 게임, 패션 등 버티컬 AI로 기존 국내 멀티모달 AI를 선도하는 NC AI가 비전언어모델에서도 한국의 주권을 지킬 수 있는 가능성을 확인했다”고 밝혔다.
글. 바이라인네트워크
<이대호 기자>ldhdd@byline.network