
[그게 뭔가요] 국가대표 AI 선발전, 누가 참가하나

우리나라를 대표할 인공지능(AI) 선발전이 열리고 있습니다. 과학기술정보통신부는 ‘독자 AI 파운데이션 모델’ 프로젝트에 참여할 정예팀을 지난 6월 20일부터 7월 21일까지 공모하고 있습니다.
‘독자 AI 파운데이션 모델’ 구축 사업은 6개월 이내 출시한 최신 글로벌 AI 모델 대비 95% 이상 성능 구현을 목표로, 글로벌 경쟁력을 갖춘 독자 AI 파운데이션 모델을 개발하는 프로젝트입니다. 전 세계적으로 AI 패권 경쟁이 치열해지면서 우리나라도 경쟁력을 갖춘 자체 AI 모델 구축에 나선 거죠. 1차 추가 경정 예산 1576억원 규모로 그래픽처리장치(GPU), 데이터, 인재를 종합 지원하는 대규모 프로젝트입니다.
선발된 정예팀은 ‘한국형 인공지능 모형(K-AI 모델)’ 혹은 ‘한국형 인공지능(K-AI) 기업’ 등의 명칭을 쓸 수 있습니다. 이번 프로젝트로 개발할 독자 AI 파운데이션 모델은 오픈소스로 공개해 우리나라 경제 사회 전반에 걸쳐 AI 전환과 기술 발전의 기반이 될 예정입니다.

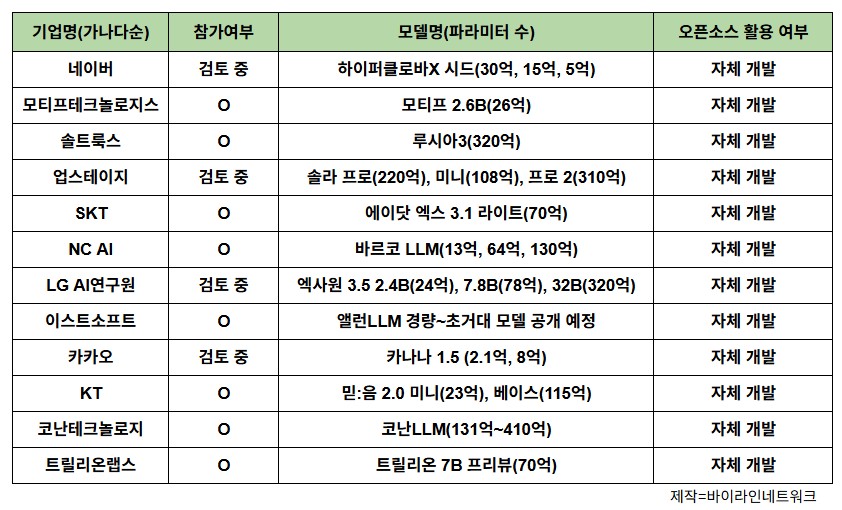
K-AI 모델 사업에 도전장을 내민 기업과 아직 긍정적으로 검토하는 기업 등 다양한데요. ‘모두의 AI’의 출발점이 될 이 프로젝트, 각 기업들은 어떤 대규모언어모델(LLM)을 갖추고 있는지 좀 더 자세히 살펴보겠습니다. 순서는 기업명 기준으로 가나다순입니다.
네이버, 하이퍼클로바X (HyperCLOVA X)
네이버가 지난 2023년 공개한 하이퍼클로바X는 해외 경쟁사 모델 대비 6500배 많은 순수 한국 데이터를 이용해 학습했습니다.
‘KMMLU’, ‘HAERAE’, ‘KorNAT’ 등 여러 벤치마크에서도 우수한 점수를 기록했습니다. 영어, 중국어, 일본어 등 다양한 언어를 지원하고 한국어 특화된 토크나이저를 활용합니다. 이미지나 음성 정보를 한국어로 추론하는 네이티브 멀티모달 확장성을 갖췄습니다.
네이버는 지난 6월 추론 능력을 강화한 생성형 AI 모델 ‘하이퍼크로바X 씽크’를 선보였고, 해당 모델이 한국어 전문가 레벨 평가에서 비교군 중 최고 수준 점수를 기록했다고 강조했습니다. 하이퍼클로바 X 씽크는 LLM의 깊이 있는 한국어 이해도 진단을 위한 전문가 수준 문항으로 구성된 ‘KoBALT-700’ 벤치마크와 ‘HAERAE’ 벤치마크 등에서 유사 규모 국내외 주요 오픈소스 모델보다 높은 점수를 기록했다고 합니다.
네이버는 해당 모델이 언어뿐 아니라 시각 정보를 바탕으로 추론할 수 있는 기술도 있다고 소개했습니다. 테크니컬 리포트에 따르면 하이퍼클로바X 씽크는 멀티모달 추론을 겨냥해 만들지 않았지만, 시각 추론 영역에서 정답을 맞히는 모습을 보였습니다. 이 외에도 네이버는 오픈소스 경량모델 ‘하이퍼클로바X 시드’와 실용형 경량모델 ‘하이퍼클로바X 대시’ 등을 갖추고 있습니다. 하이퍼클로바X 시드는 30억, 15억, 5억 파라미터 규모로 세분화되어 있습니다.
네이버는 추론모델 하이퍼클로바X 씽크를 추후 오픈소스로 공개할 계획이며, 사업을 긍정적으로 검토하고 있습니다.
모티프테크놀로지스, 모티프 2.6B
AI 인프라 기업 모레 자회사 모티프테크놀로지스는 지난 6월 프롬 스크래치로 개발한 소형언어모델(sLLM) ‘모티프 2.6B’를 오픈소스로 허깅페이스에 공개했습니다.
경량화된 고성능 AI 모델을 표방하는 모티프 2.6B는 이름처럼 26억개 파라미터를 가졌습니다. 모티프테크놀로지스는 해당 모델이 70억개 파라미터 규모 모델 성능을 능가한다고 강조했습니다. 2025년 6월 기준 미스트랄 7B 대비 134% 성능을 보였습니다.
모티프테크놀로지스는 엔비디아 칩이 아닌 AMD 기반으로 AI 모델을 구축하고 있습니다. 카이스트, 서울대 및 여러 기업과 컨소시엄을 준비해 해당 사업에 참여할 예정입니다.
솔트룩스, 루시아3(LUXIA 3)
솔트룩스는 지난 5월 자체 개발 LLM ‘루시아3’을 공개했습니다. 솔트룩스는 올해 2월 루시아 2.5 버전을 선보인 뒤 3개월 만에 최신 버전 루시아를 내놨습니다.
루시아3은 ▲언어 생성 및 이해에 특화 모델 ‘루시아3 LLM’ ▲복잡한 추론과 판단 수행 모델 ‘루시아3 딥(Deep)’ ▲비정형 정보 분석 모델 ‘루시아3 VLM’으로 총 3가지입니다. 파라미터 수는 320억개입니다.
루시아3은 질문이 복잡하면 더 길게 사고하고, 일상적이고 간단한 질문에서는 빠르게 답변하는 특징을 가졌습니다.
업스테이지, 솔라(Solar)
업스테이지는 지난 2020년 설립된 AI 스타트업입니다. 자체 개발 LLM ‘솔라’를 보유하고 있습니다.
모델은 프로와 미니, 최근 공개한 프로 2까지 3종입니다. 파라미터 수는 프로 220억개, 미니 108억개, 프로 2는 310억개 규모입니다.
업스테이지는 솔라 프로 2를 공개하면서 파라미터 규모가 기존 프로 220억개에서 310억개로 확장한 데 이어, 하이브리드 모드를 도입했습니다. 사용자는 빠른 응답에 최적화된 ‘챗 모드’와 구조화된 답변을 생성하는 ‘추론 모드’ 중 상황에 따라 선택할 수 있습니다.
업스테이지에 따르면 솔라 프로 2는 종합지식(MMLU-Pro), 수학(Math500, AIME), 코딩(SWE-Bench) 등 고난도 추론 중심 벤치마크에서 오픈AI ‘GPT-4o’, 딥시크 ‘R1’, 미스트랄 ‘스몰 3.2’, 알리바바 ‘큐원 3’ 등에 필적했습니다. 업스테이지는 솔라 프로 2를 세계적인 수준의 LLM을 자체 기술로 구현했다고 강조했습니다.
업스테이지는 작지만 강력한 소형언어모델(sLLM)이 특징입니다. 오픈AI의 챗GPT가 파라미터 1000억개 규모를 넘어가는 데 비해, 소형언어모델은 상대적으로 적은 수의 파라미터를 갖고 있습니다. 업스테이지는 금융, 보험, 법률 의료 같이 특정 산업군에 특화된 sLLM을 지향합니다.
업스테이지는 지난 6월 AI 반도체 팹리스 기업 퓨리오사AI와 손잡고, 국산 NPU에 국산 LLM 솔라를 탑재할 예정이라고 밝혔습니다.
SKT, 에이닷엑스(A.X)
SK텔레콤(SKT)은 한국어 처리 능력을 강조하는 한국어 특화 LLM 에이닷 엑스(A.X) 4.0을 이번 달 오픈소스로 공개했습니다. A.X 4.0 모델은 표준과 경량으로 2종입니다.
해당 모델은 알리바바의 오픈소스 모델 ‘큐원 2.5’에 한국어 데이터를 학습시켜 만들었습니다. SKT는 토크나이저를 자체 설계해 한국어 처리 역량을 높은 수준으로 구현했습니다. 자체 테스트 결과 같은 한국어 문장을 입력했을 때, 오픈AI의 GPT-4o보다 에이닷 엑스 4.0이 약 33%가량 높은 토큰 효율을 기록했습니다. 한국어 능력 평가 벤치마크 KMMLU에서 78.3점으로 GPT-4o(72.5점)보다 높은 점수를 달성했습니다. 한국어 및 한국 문화 벤치마크인 CLIcK에서는 83.5점을 획득해, GPT-4o(80.2점)보다 더 높은 한국 문화 이해도를 보였습니다.
SKT는 에이닷 엑스 4.0을 기업 내부 서버에 직접 설치해 사용할 수 있는 온프레미스 방식으로 제공해 데이터 보안 걱정을 덜 수 있습니다. 표준 모델은 720억 파라미터 규모, 경량 모델은 70억 파라미터 규모를 갖췄습니다.
또, SKT는 독자 구축 LLM 에이닷 엑스 3.1 라이트를 오픈소스로 공개할 예정입니다. SKT는 해당 모델이 프롬 스크래치 방식으로 초기 단계부터 모두 직접 구축한 경량모델로, 파라미터 수 70억 개(7B)를 바탕으로 작동한다고 설명했습니다.
SKT는 이번 사업에 에이닷 엑스 3.1 라이트 모델로 참여할 예정이며, 프롬 스크래치 방식 모델을 지속 고도화해 나가겠다고 밝혔습니다.
NC AI, 바르코 LLM(VARCO LLM)
국내 게임사도 사업에 도전합니다.
올해 2월 엔씨소프트는 AI 전문 자회사 NC AI를 출범시켰습니다. 엔씨소프트의 14년 AI 연구 노하우를 바탕으로 AI 솔루션에 집중하고자 분사했습니다.
엔씨소프트는 지난해 자체 개발 언어모델 ‘바르코 LLM’을 공개했습니다. 국내 게임사에서는 처음으로 자체 개발한 언어 모델로 파라미터 13억, 64억, 130억개 규모입니다. 바르코 언어모델은 기초 모델, 인스트럭션 모델, 대화형 모델, 생성형 모델 총 4종류이고 파라미터 규모에 따라 성능을 구분합니다.
지난해 4월에는 바르코 LLM 2.0 버전을 깃허브와 아마존웹서비스(AWS)에 공개했습니다. NC AI는 앞으로도 LLM 모델을 오픈소스로 공개할 예정이며, 게임 제작이나 콘텐츠 제작, 패션 등 다양한 분야에서 사업화를 준비하고 있습니다.
LG AI연구원, 엑사원(EXAONE)
LG AI연구원은 오픈소스 모델 ‘엑사원 3.5’와 추론 모델 ‘엑사원 딥’을 개발했습니다. 엑사원 1.0은 2022년 처음 공개됐고, 작년 12월에 엑사원 3.5까지 나왔습니다. 지난 3월에는 추론 강화 모델 엑사원 딥(EXAONE Deep)을 선보였고, 엑사원 4.0은 개발 중이며 조만간 공개 예정입니다.
엑사원 3.5 기반 모델은 ▲초경량 모델 2.4B ▲경량 모델 7.8B ▲프론티어 AI급 고성능 32B 등 3가지로 구성됐습니다. 모델명처럼 파라미터 수는 순서대로 24억, 78억, 320억입니다.
엑사원은 자신 있게 벤치마크 성능을 강조했습니다. 3가지 모델 모두 장문 이해 기능 등 7개 벤치마크에서 큐원(Qwen) 2.5나 라마(Llama) 3.2 모델 등을 앞섰습니다.
미국 스탠포드대 인간중심 인공지능 연구소(HAI)에서 매년 발간하는 ‘AI 인덱스 2025’ 보고서에 따르면, ‘주목할 만한(Notable)’ AI 모델로 우리나라 모델 중 유일하게 ‘엑사원 3.5’가 선정되기도 했습니다.
이스트소프트, 앨런 LLM(Alan LLM)
이스트소프트는 자체 개발 LLM ‘앨런 LLM’을 지난 6월 정식 출시하면서 사업에 도전장을 내밀었습니다.
앨런LLM은 현재 서비스 중인 AI 검색 엔진 앨런의 노하우를 바탕으로 만들어졌습니다. 검색증강생성(RAG) 기반 보고서 생성이 가능하고 추론에 특화된 오픈소스 기반 모델입니다.
데이터센터용 초거대 모델부터 온디바이스용 경량 모델까지 구성했고, 경량 모델부터 하반기에 순차적으로 공개할 예정입니다. 초거대 모델은 파라미터 2000억개 규모 이상으로 알려졌습니다.
카카오, 카나나 1.5(Kanana 1.5)
카카오는 지난해 10월 카카오 서비스에 최적화된 자체 개발 AI 모델 라인 ‘카나나 모델 패밀리’ 10종을 소개했습니다. 크게 언어모델 3종, 멀티모달 언어모델 3종, 비주얼 생성 모델 2종, 음성 모델 2종 등으로 구분되고, 크기와 기능에 따라 세부 모델로 나뉩니다.
그리고 지난 2월 공개한 자체 언어모델 카나나 1.0은 ▲초경량 ‘카나나 나노’ ▲고성능 중소형 ‘카나나 이센스’ ▲최고 성능 ‘카나나 플래그’로 나뉩니다.
카카오는 카나나 1.0 공개 3개월 후, 지난 5월 업그레이드된 카나나 1.5를 8억개 파라미터 규모 중형 모델과 2.1억개 파라미터 규모 경량 모델 2종을 오픈소스로 공개했습니다. 그중 카나나 1.5 8억개 중형 모델은 지난 6월 기준 한국어 LLM 성능 평가 벤치마크 플랫폼 ‘호랑이 리더보드’에서 80억개 이하(8B) 국내 모델 중 가장 높은 점수를 받기도 했습니다.
현재 카카오는 ‘오픈소스를 뛰어넘는 카카오 서비스에 최적화된 LLM’을 목표로 카나나 2를 개발하고 있습니다. 앞으로도 오픈소스로 공개할 예정입니다.
KT, 믿:음 2.0
KT가 믿:음 2.0으로 사업에 도전합니다.
믿:음 2.0은 KT가 이번 달 공개한 ‘한국적 AI’의 철학을 담은 자체 개발 LLM입니다. 해당 모델은 오픈소스로 AI 개발자 플랫폼 허깅페이스를 통해 공개됐고, 모델은 ‘믿:음 2.0 미니(mini)’과 믿:음 ‘2.0 베이스(base)’로 현재 총 2종입니다.
여기서 ‘한국적 AI’는 한국의 정신과 방식, 지식을 기반으로 구현해 한국에 가장 잘 맞는 AI를 의미합니다. AI 철학으로 한국적 AI를 추구하는 KT는 우리나라의 사회적 맥락과 같은 무형 요소와, 한국어 고유의 언어적·문화적 특성 등을 학습한 AI 모델을 개발했습니다.
KT의 믿:음은 사전 학습부터 자체적으로 만든 한국적 독자 AI 모델로서 고품질 한국어 데이터를 준비하는 과정에서 모든 저작권을 확보해 신뢰성을 높였습니다. 한국어를 강조하는 만큼, 한국어 AI 역량 평가 지표 ‘코-소버린(Ko-Sovereign)’ 벤치마크, 한국과 관련한 전문 지식의 이해도를 측정하는 벤치마크 ‘KMMLU’, 한국어 언어모델 평가 지표 ‘HAERAE’ 등에서 유사 규모 타 모델 대비 우수한 성능을 기록했다고 합니다. 또, KT는 한국어의 구조와 언어학적 특성을 반영한 토크나이저를 자체 개발하고, 필터링으로 줄어든 데이터 규모는 데이터 합성 방법론을 적용해 보완했습니다.
믿:음 2.0 베이스는 115억 파라미터 규모, 믿:음 2.0 미니는 23억 파라미터 규모로 한국어와 영어를 지원합니다. 믿:음 2.0 베이스는 범용 서비스에 적합하고, 믿:음 2.0 미니는 베이스 모델에서 증류한 지식을 학습한 소형 모델입니다.
코난테크놀로지, 코난 LLM(Konan LLM)
사업에 도전하는 코난테크놀로지는 지난 2023년 자체 개발 LLM ‘코난 LLM’을 출시했습니다. 지난 4월에는 일반 모델과 추론 모델을 통합한 모델 ‘코난 LLM ENT-11’을 공개했습니다. 코난테크놀로지에 따르면 해당 모델은 작문, 추론, 코딩 등 8개 항목에서 딥시크 R1 모델을 능가했습니다.
모델은 ▲온디바이스 ‘On-device(OND)’ ▲프로페셔널 ‘Professional(PRO)’ ▲엔터프라이즈 ‘Enterprise(ENT)’로 3가지이며, 기업 규모나 목적, 예산에 따라 선택할 수 있습니다. 파라미터 수는 131억개에서 410억개 규모로 다양합니다.
코난테크놀로지는 지난 6월 리벨리온과 협력해 국산 NPU에 코난 LLM을 결합할 예정이라고 밝혔습니다.
트릴리온랩스, 트릴리온 7B(Trillion-7B)
마지막 트릴리온랩스는 한국어 LLM 사전 학습 과정에 직접 참여 경험이 있는 팀으로 사업에 도전합니다.
트릴리온랩스는 한국어 기반 LLM을 개발하고 있는 스타트업입니다. 네이버 하이퍼클로바X 핵심 연구자 출신 신재민 대표가 지난해 설립해 420만달러(약 57억원) 규모 프리시드 투자 유치에 성공하기도 했습니다.
트릴리온랩스는 올해 3월 70억개 파라미터 규모 ‘트릴리온 7B 프리뷰’를 오픈소스로 공개했습니다. 핵심 기술은 ‘언어 간 상호학습 시스템(XLDA)’입니다. 설명에 따르면 영어나 중국어는 데이터가 많아 성능을 끌어올리기 쉽지만, 데이터가 제한적인 언어에는 한계가 있습니다. XLDA 기술은 이 한계를 극복할 수 있도록 한국어나 일본어 같은 저자원 언어를 효과적으로 전달할 수 있게 설계했습니다. 구체적으로 영어 문서와 한국어 문서를 동시에 학습하면서 서로의 강점만 공유하는 방식으로 작동합니다.
트릴리온랩스의 첫 번째 목표는 ‘한국에서 가장 강력한 파운데이션 모델 구축’입니다. 한국어를 시작으로 아시아 언어 LLM을 구축하고 있습니다.
살펴보니 국내에 꽤 많은 LLM들이 있네요. 이 외에도 소개하지 못한 기업이나 아직 개발하고 있는 LLM들이 많을 듯합니다. 과기부는 최대 5개 정예팀을 선발한다고 밝혔습니다. 이후 단계평가로 경쟁해 4개팀, 3개팀, 2개팀 등으로 압축해 나갑니다. 미래 인공지능 인재를 육성한다는 관점에서 대학생(또는 대학원생) 참여를 필수로 합니다. 과연 이 중에서 ‘K-AI 모델’이 될 LLM이 있을지 기대됩니다.
글. 바이라인네트워크
<최가람 기자> ggchoi@byline.network