
구글, 오픈 모델 ‘젬마 4’ 출시
구글이 오픈웨이트 모델의 최신 버전인 ‘젬마 4(Gemma 4)’을 발표했다. 구글은 고급 추론과 에이전트 기반 워크플로우를 위해 특수 설계된 모델이라고 강조했다.
구글 젬마는 첫 버전 출시 후, 4억회 이상 다운로드를 기록했으며, 10만개 이상의 파생 모델로 퍼졌다. 젬마 4는 아파치 2.0 라이선스로 제공돼 누구나 활용할 수 있다.
구글은 제미나이 3와 동일한 세계 최고 수준의 연구 및 기술을 기반으로 개발됐으며, 이용자의 하드웨어에서 강력한 성능을 제공한다고 강조했다.

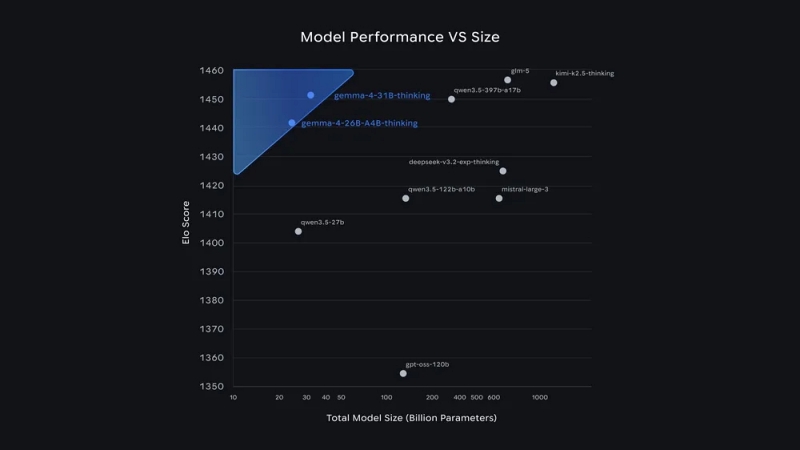
젬마 4는 4개 크기로 제공된다. ▲Effective 2B (E2B) ▲Effective 4B (E4B) ▲26B Mixture of Experts (MoE) ▲31B Dense 등이다. 31B 모델은 현재 업계 표준인 아레나 AI 텍스트 리더보드(Arena AI text leaderboard)에서 오픈 모델 기준 3위, 26B 모델은 6위를 기록했다. 젬마 4는 20배 큰 모델도 압도하는 성능을 보였다.
E2B와 E4B 모델은 온디바이스 AI에 특화됐다. 두 모델은 매개변수 수보다 멀티모달 기능, 낮은 레이턴시, 생태계와 원활한 연동을 우선적으로 고려해 설계됐다.
구글은 “차세대 혁신 연구 및 제품 개발을 지원하기 위해, 구글은 젬마 4 모델이 전 세계 수십억 대의 안드로이드 기기부터 노트북 GPU, 개발자 워크스테이션 및 가속기에 이르기까지 하드웨어에서 효율적으로 실행되고 미세 조정될 수 있도록 설계했다”고 밝혔다.
구글은 젬마4에 대해 수학 및 수학 및 복합 지시 이행 등 고도의 지능이 요구되는 벤치마크에서 상당한 성능 향상을 입증했고, 함수 호출, 구조화된 JSON 출력 및 네이티브 시스템 지침을 기본 지원하며, 다양한 툴 및 API와 상호작용하고 워크플로우를 안정적으로 실행하는 자율형 에이전트를 구축할 수 있다고 강조했다. 그밖에 코드 생성, 이미지 및 오디오 입출력 처리, 더 긴 텍스트, 140개 이상의 언어 지원 등도 강점으로 내세웠다.
구글은 특정 하드웨어 및 사용 사례에 최적화된 다양한 크기로 젬마 4 모델 가중치(weights)를 출시하며, 이용자가 필요한 곳 어디에서나 최첨단(frontier-class) 추론 성능을 경험할 수 있도록 지원한다
26B 및 31B 모델은 개인용 컴퓨터를 위한 오프라인 기반 프런티어급 지능을 구현한다.
연구자와 개발자가 접근 가능한 하드웨어에서 최첨단 추론 성능을 제공하도록 최적화됐다. 비양자화(unquantized) bfloat16 가중치는 단일 80GB 엔비디아 H100 GPU에서도 효율적으로 실행되며, 양자화 버전은 일반 소비자용 GPU에서도 구동돼 IDE, 코드 어시스턴트, 에이전틱 워크플로우를 지원한다. 26B MoE 모델은 레이턴시에 초점을 맞춰 전체 매개변수 중 약 38억개만 활성화해 빠른 속도를 제공하며, 31B Dense 모델은 출력 품질을 중심으로 설계돼 미세 조정을 위한 기반 모델로 활용할 수 있다.
E2B 및 E4B 모델은 모바일 및 IoT 기기를 위한 지능을 구현한다. 연산과 메모리 효율성을 고려해 설계됐으며, 추론 시 각각 약 20억, 40억 규모의 파라미터만을 활용해 메모리 사용량과 배터리 소모를 최소화한다. 구글 픽셀 팀 및 퀄컴, 미디어텍 등 하드웨어 조직과 긴밀한 협력을 통해 스마트폰, 라즈베리 파이, 엔비디아 젯슨나노 등 NVIDIA 엣지 기기에서 제로에 가까운 레이턴시로 오프라인 실행된다. 안드로이드 개발자는 AI코어 디벨로퍼 프리뷰에서 에이전트 기반 흐름의 프로토타입을 제작해 제미나이 나노 4와의 향후 호환성을 확보할 수 있다.
구글 AI 스튜디오에서 젬마 4(31B 및 26B MoE)를, 구글 AI 엣지 갤러리에서 젬마 4(E4B 및 E2B)를 이용해볼 수 있다. 안드로이드 개발자는 안드로이드 스튜디오 에이전트 모드와 ML Kit GenAI Prompt API를 활용해 프로덕션 환경까지 확장할 수 있다. 허깅페이스, vLLM, 올라마, 엔비디아 NIM 등에서도 이용할 수 있다. 모델 가중치는 허깅페이스, 캐글, 올라마에서 다운로드 받을 수 있다.
젬마 4는 주요 하드웨어 환경에 최적화돼 제공된다. 엔비디아 젯슨나노와 블랙웰 GPU뿐 아니라, 오픈소스 ROCm 스택을 통해 AMD GPU와도 연동된다. 구글 클라우드 TPU를 활용해 대규모로 확장할 수 있다.
글. 바이라인네트워크
<김우용 기자>yong2@byline.network