
트릴리온랩스, 차세대 LLM ‘트리-21B’ 오픈소스 공개
트릴리온랩스(대표 신재민)는 단순한 텍스트 생성 능력을 넘어 고차원적 언어 이해와 복잡한 문제 해결을 동시에 수행할 수 있도록 설계된 차세대 대규모언어모델(LLM) ‘트리(Tri)-21B’를 오픈소스로 공개했다고 23일 밝혔다.
트리-21B는 전작 트릴리온-7B 대비 파라미터 수를 3배 이상 확장한 약 210억개 규모로 성능을 대폭 끌어올렸다. 1대의 GPU에서도 원활하게 작동할 수 있는 경량성과 효율성을 동시에 갖췄다.
트릴리온랩스는 이번 모델을 자체 기술력으로 LLM 엔진부터 완전한 사전학습 방식(프롬 스크래치)으로 개발했다. 고정밀 추론이 필요한 작업에서 강력한 성능을 발휘하도록 설계해, 수학과 코딩 등 단계적 사고가 요구되는 문제에 대해 구조화된 답변을 생성하는 생각사슬(CoT) 구조를 채택했다. 트릴리온랩스는 자사만의 기술력인 언어 간 상호학습 시스템(XLDA)을 적용했다.

XLDA는 영어 기반 지식을 한국어 및 일본어와 같은 저자원 언어로 효과적으로 전이하는 데이터 학습 방법론이다. 기존 대비 1/12 수준으로 학습 비용을 절감할 수 있다. 데이터가 부족한 산업 분야에서도 LLM 활용도를 끌어올릴 수 있는 기반이 될 수 있다. 트릴리온랩스에 따르면 XLDA를 활용하면 한국어뿐 아니라 데이터가 적은 일본어와 같은 동북아 언어권에서도 더욱 자연스럽고 정확한 문장 생성을 할 수 있다는 장점이 있다.
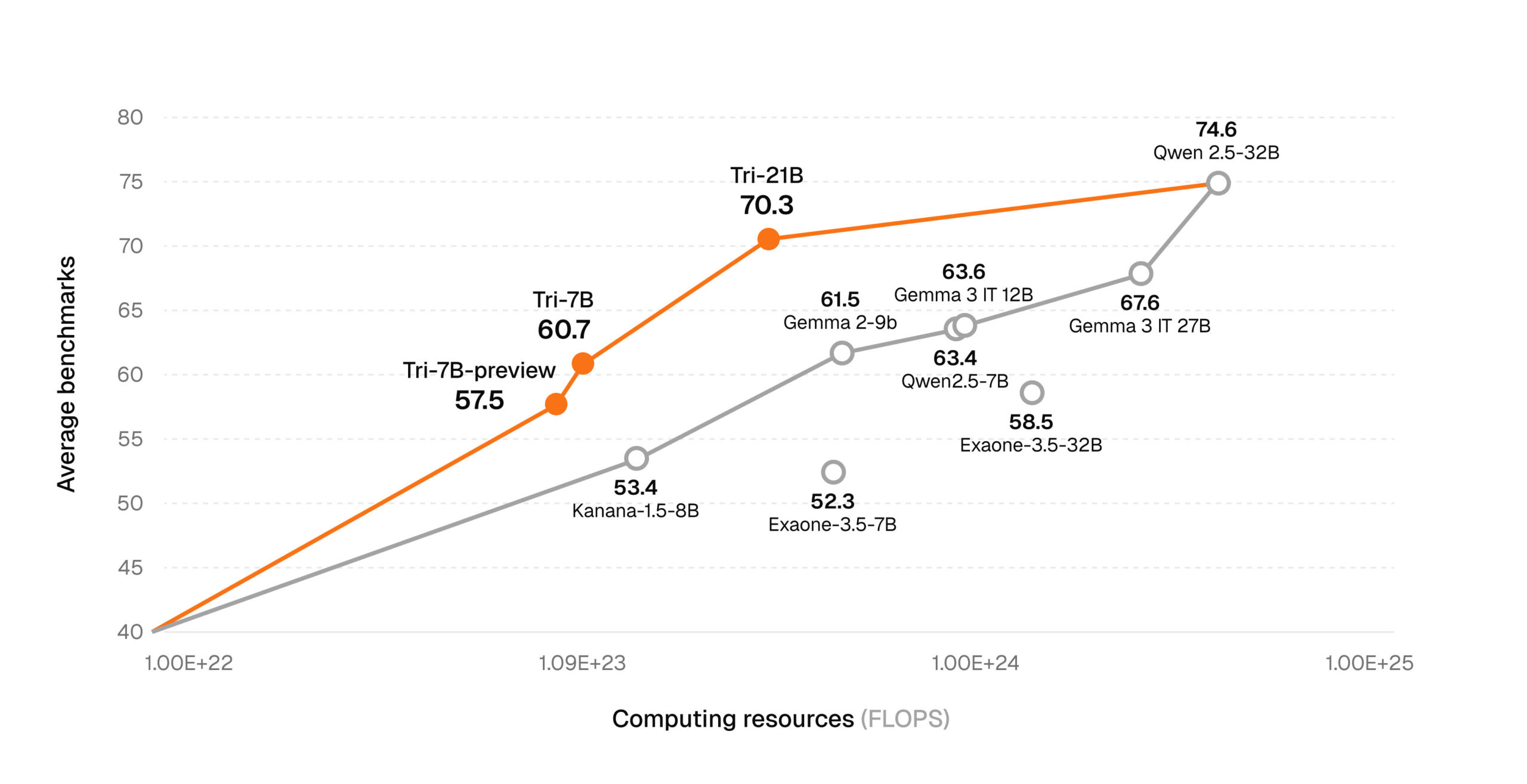
트릴리온랩스에 따르면 트리-21B는 종합지식(MMLU), 한국어 언어 이해(KMMLU), 수학(MATH), 코딩(MBPP Plus) 등 고난도 추론 중심 벤치마크에서 알리바바 큐원3, 메타 라마3, 구글 젬마3 등 글로벌 대표 중형 모델과 견줄만한 성능을 보였다. 특히 추론능력 검증에서는 77.93(CoT 적용시 85)점, 수학에서 77.89점, 코딩 영역에서 75.4점의 정확도를 기록해 실제 문제 해결 능력에서도 강점을 보였다.
주요 한국어 벤치마크에서도 두각을 드러냈다. 한국문화의 이해도를 측정하는 해례(Hae-Rae)에서 86.62점, 한국어 지식과 추론능력(KMMLU)에서 62점(CoT 적용시 70)을 기록했다. 글로벌 모델 대비 높은 점수를 기록해 어휘와 문맥 이해, 문화적 맥락 반영에서 높은 한국어 이해 능력을 보였다. 금융, 의료, 법률 등 높은 신뢰도가 요구되는 분야에서도 안정적인 결과를 도출해, 산업 전반에 걸친 적용 가능성을 높였다.
신재민 트릴리온랩스 대표는 “트리-21B는 플라이휠 구조를 통해 70B급 대형 모델의 성능을 21B에 효과적으로 전이해 모델 사이즈와 비용, 성능 간 균형에서 현존하는 가장 이상적인 구조를 구현했다”며 “이 모델처럼 바닥부터 사전학습으로 개발한 고성능 LLM을 통해 비용 효율성과 성능 개선을 빠르게 달성해 한국 AI 기술력의 완성도를 높이고, 향후 공개될 트리-70B와 함께 풀사이즈 LLM 포트폴리오를 완성해 나가겠다”고 강조했다.
글. 바이라인네트워크
<최가람 기자> ggchoi@byline.network