

GPU 상호연결 ‘UA링크 1.0’ 엔비디아 장벽 허물까

엔비디아의 GPU 상호연결 기술 ‘NV링크’ 대체를 노리는 ‘울트라액셀러레이터링크(UA링크)’가 드디어 첫 사양을 공개했다.
UA링크컨소시엄은 지난 8일 ‘UA링크 200G 1.0’ 사양을 공식 발표했다. 현재 UA링크컨소시엄 홈페이지에서 사양을 다운로드 할 수 있다.
UA링크컨소시엄은 2024년 5월 출범한 단체로, AI 가속 장치의 상호연결을 위한 개방형 표준 구축을 목표로 한다. AMD, AWS, 브로드컴, 시스코, 구글, HPE, 인텔, 메타, 마이크로소프트 등이 참여해 설립했다. 현재 70개 이상의 기여자와 기업이 참여중이다.
UA링크컨소시엄은 작년 초당 200기가비트(Gbps)급 GPU 상호연결 사양을 올해 1분기 중 공개하겠다고 밝혔었다. 하지만 UA링크 1.0 공개는 예정보다 지연됐다.
커티스 보우만 UA링크컨소시엄 이사회 의장은 “AI 컴퓨팅에 대한 수요 증가에 따라 차세대 AI/ML 애플리케이션을 지원하는 필수적인 개방형 산업 표준 기술을 시장에 제공하게 돼 기쁘다”며 “UA링크는 전력, 지연 시간, 비용을 낮추면서 효과적인 대역폭을 늘리는 데 최적화된 스케일업 AI를 위한 유일한 메모리 시맨틱 솔루션”이라고 밝혔다.
그는 “UA링크 200G 1.0 사양의 획기적인 성능은 클라우드 서비스 제공업체, 시스템 OEM, IP/실리콘 공급업체가 AI 워크로드에 접근하는 방식에 혁신을 가져올 것”이라고 강조했다.
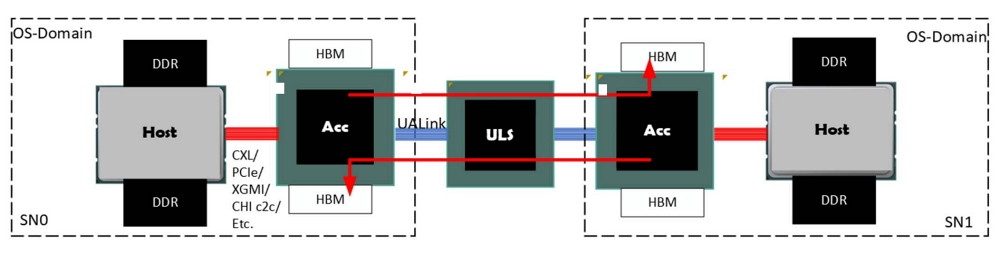
UA링크 1.0 사양 훑어보기
UA링크 1.0은 GPU 가속기의 상호연결을 PCI익스프레스와 이더넷 기술 기반으로 제공한다. AMD가 인피니티패브릭 프로토콜을 제공했고, 참여 기업들이 PCI익스프레스 표준 사양에서 불필요한 요소를 제거해 새로운 데이터 계층과 전송 계층을 만들고 수정된 이더넷 SerDes 세트와 결합했다.
공개된 사양에 따르면, UA링크 1.0은 레인당 200Gbps의 고대역폭으로 GPU 가속기를 연결할 수 있다. AI POD 내 최대 1024개의 가속기를 단일 클러스터로 통합할 수 있다고 한다.
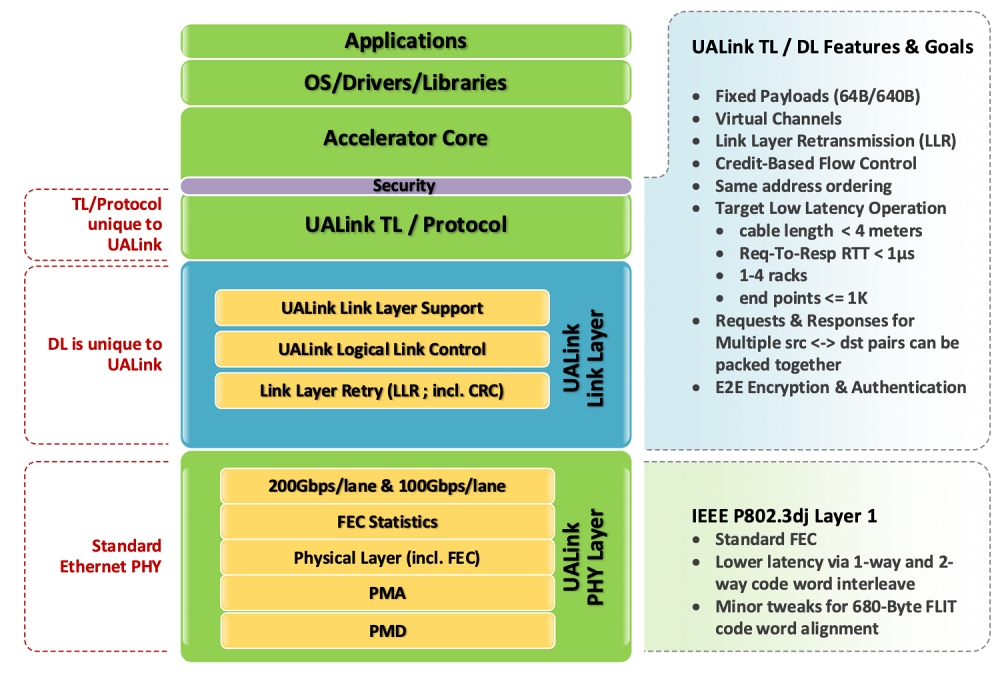
아키텍처는 프로토콜, 트랜잭션, 데이터링크, 물리 등의 4 계층으로 구성된다.
물리 계층(PL, IEEE P802.3dj)은 표준 순방향 오류 정정(FEC) 기능과, 단방향 및 양방향 코드워드 인터리브(interleave)로 지연시간을 최적화했다. 680바이트 플릿(flit)을 지원하기 위해 IEEE 802.3 표준을 변경했다.
이더넷 SerDes를 탑재해 데이터의 직렬화와 병렬화를 할 수 있다. 이는 물리 계층에서 고대역폭을 실현하고, 케이블 복잡성을 줄이며, 긴 거리 전송 시 신호 품질을 유지하게 한다.
포트 당 직렬 레인을 1, 2 또는 4개 구성할 수 있다. 레인을 100Gbps와 200Gbps로 생성할 수 있다. 200Gbps 레인 4개를 구성하는 경우 최대 800Gbps 대역폭을 제공하고, 여러 포트를 통합해 가속기를 1024개까지 확장할 수 있다.
데이터링크 계층(DL)은 물리 계층과 트랜잭션 계층 사이에 위치하며, 데이터 패킹, 메시지 서비스, 데이터 안정성 확보, 흐름 제어 등의 기능을 제공한다. 64B의 작은 데이터 조각을 모아 640B 크기의 데이터 묶음으로 만들어 물리 계층으로 전송한다. 메시지 서비스를 통해 장치가 얼마나 빠르게 데이터를 처리할 수 있는 지 알려주고, 연결된 장치의 ID를 확인하며, 장치 펌웨어 간 통신을 위한 간단한 메시지 채널을 제공한다.
640바이트 데이터 묶음마다 32비트 오류검사코드(CRC)를 추가한다. 데이터 손상 시 링크계층재전송(LLR)으로 데이터를 다시 보낸다.
신호 기반 흐름 제어 기능은 송신 측의 데이터 속도를 조절하고, 수신 측의 데이터 처리 속도에 맞춘다.
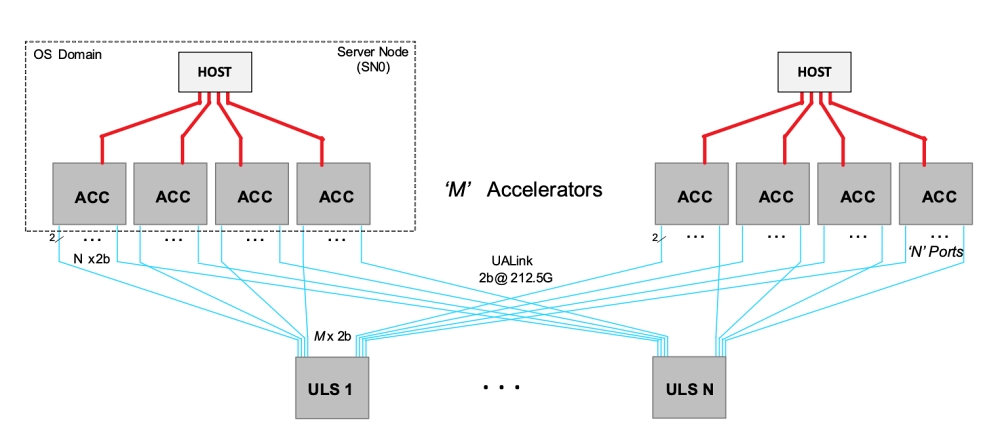
트랜잭션 계층(TL)은 가속기의 프로토콜 메시지를 네트워크 언어로 변환하고, 네트워크 언어 메시지를 다시 가속기 언어로 변환한다. 반복되는 주소 정보를 매번 다시 보내지 않고 캐시에 저장해 재사용해 동시에 많은 데이터를 효율적으로 주고 받을 수 있게 했다.
UA링크는 ‘UALinkSec’이란 보안 기능을 내장한다. UA링크 네트워크 및 스위치의 트래픽을 물리적 공격자로부터 보호한다. 컨피덴셜컴퓨팅(CC) 플랫폼에서 인프라 제공자와 다른 테넌트로부터 데이터를 보호할 수 있다. 모든 UL링크 프로토콜 인터페이스(UPLI) 채널의 암호화와 인증을 지원한다. 인텔TDX, AMD SEV, ARM CCA 등의 실행환경과 함께 작동한다.
컨소시엄 측은 93%의 유효 피크 대역폭을 달성하는 결정론적 성능을 위해 설계됐으며, 전력과 복잡성을 줄이는 고효율 스위치 설계를 가능하게 한다고 강조했다.
UA링크는 동급의 이더넷 ASIC 다이와 비교해 3분의1 전력만 사용하며, 메모리 패브릭에서 가속기당 150~200와트(W) 사이의 전력을 절감할 수 있다.
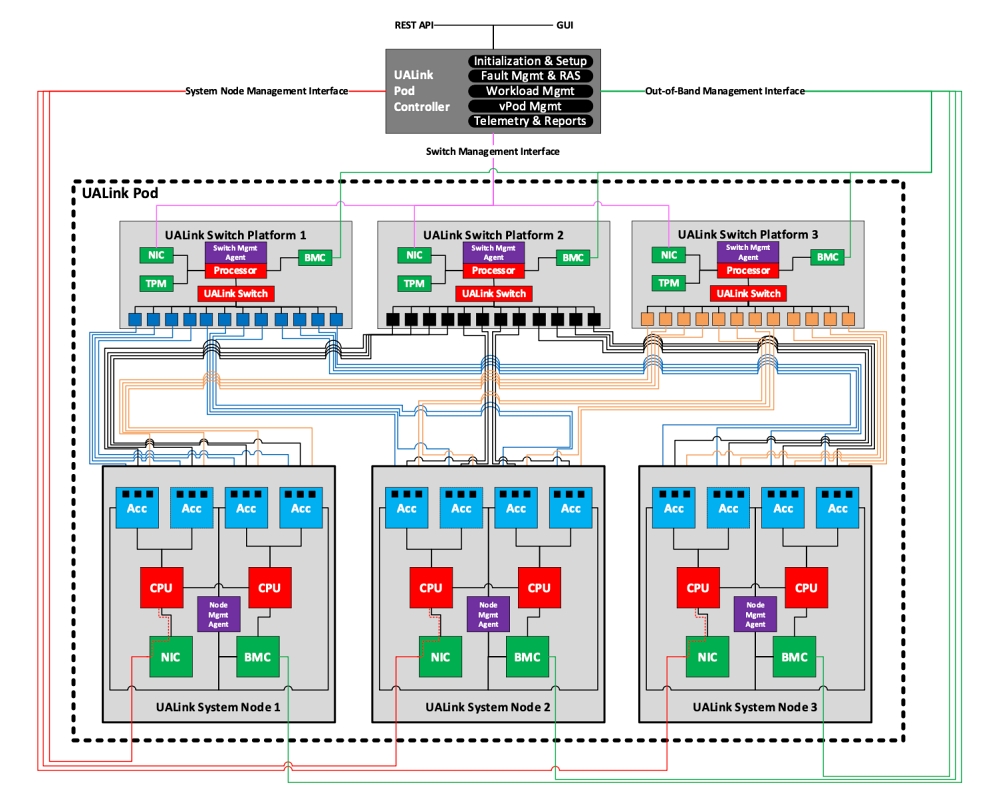
UA링크 1.0을 기반으로 랙 규모의 POD를 구축할 수 있다. UA링크 POD 컨트롤러로 POD를 관리한다. 각 가속기는 UA링크 시스템 노드에 호스팅되고, 가속기 트래픽은 UA링크 스위치를 패브릭을 거쳐 라우팅될 수 있다. 여러 개의 UA링크 POD를 연결해 더 큰 규모의 클러스터도 구성할 수 있다. 단, POD 간 통신과 제어는 UA링크 사양에 명시하지 않는다.
공개된 UA링크 1.0 백서에서 POD 구성 예시는 3개의 포트를 갖는 UA링크 가속기 4개와 호스트 CPU 2개, NIC, BMC 등으로 구성된 시스템 노드를 기본으로 한다. 3개의 시스템 노드는 3개의 UA링크 스위치 플랫폼으로 상호 연결된다. UA링크 스위치는 가속기 간의 트래픽 라우팅을 담당하고, 스위치 관리 에이전트란 펌웨어에 의해 관리된다. 이 펌웨어는 라우팅 및 가상 POD 생성을 위해 여러 스위치로 분할될 수 있다.
UA링크는 AI 가속기에 별도의 인터페이스를 사용하지 않고 기존 이더넷 인프라를 활용할 수 있다. 네트워크 및 스위치 제조사는 UA링크를 지원하는 네트워크 카드와, 이더넷 스위치를 개발하고, AI 가속기 개발사는 UA링크로 연결되는 가속기 클러스터를 제공할 수 있다.
사양에 의해 가속기를 1024개로 확장할 수 있다는 건 엔비디아보다 더 큰 확장성을 제공한다는 의미다. 엔비디아의 NV링크4와 NV스위치3 패브릭은 최대 256개의 GPU를 지원하도록 설계됐지만 상용 제품에선 8개의 GPU만 지원했다. NV링크5와 NV스위치4의 경우 이론적으로 최대 576개의 GPU를 지원하는데, 블랙웰(B200)이나 블랙웰울트라(B300)을 탑재하는 엔비디아 DGX NVL72는 GPU를 최대 72개까지 연결한다.
UA링크 1.0 사양이 왜 중요한가
일반적으로 여러 기업의 연합으로 만들어진 기술 사양이 실제 제품으로 출시되기까지 수년씩 걸리기도 한다. 하지만 UA링크 제품은 단 시간 내 출시될 것으로 예상된다.컨소시엄 측은 12~18개월 내 제품이 출시될 것으로 예상한다.
브로드컴, 인텔, AMD 등이 적극적으로 움직이고, 네트워크 장비업체가 AI 인프라 시장에서 유의미한 반응을 이끌어내면 엔비디아도 UA링크를 병행 채택할 가능성도 있다.
현재 생성형 AI와 대형언어모델(LLM)의 학습, 추론에서 GPU는 필수다. 그리고 압도적 성능과 소프트웨어를 확보한 엔비디아가 AI GPU 인프라 시장을 사실상 독점하고 있다. 엔비디아는 자사 GPU 탑재 서버의 여러 GPU를 연결하는 기술로 NV링크를 제공하고, 단일 시스템 내 GPU 상호연결에 NV스위치를 활용하라고 가이드한다.

NV링크와 NV스위치는 엔비디아의 독점 기술이며, 엔비디아의 GPU 인프라 수직계열화를 달성하게 한 핵심이다. 엔비디아는 GPU 서버와 GPU 서버의 네트워크에서도 인피니밴드 표준을 독점 제공하고 있다.
AI 인프라에서 기존 이더넷 기술을 활용하는 사례가 늘어나고 있는 반면, 시스템 내부의 GPU 연결에서 NV링크를 대체할 기술은 사실상 없다. AMD, 인텔 등의 자체 기술은 사양에서 뒤처진다.
기존 이더넷 네트워킹 솔루션 제공기업은 엔비디아와 AI 관련 사업에서 협력하면서도 동시에 엔비디아와 경쟁해야 하는 불리한 입장이다. PCIe와 CXL을 활용하는 방안이 연구되고 있지만 비관적 의견이 다수다.
UA링크는 사실상 대체불가능한 NV링크를 겨냥했고, AI 인프라 시장의 결정적 균열을 만들 수 있는 가능성을 가졌다. 거의 대부분의 칩 제조사와 네트워킹 솔루션 기업, 서비스기업이 동참하고 있어서 잠재적인 기술 채택 기반도 마련돼 있다.UA링크는 AI 인프라에서 점점 그 중요성이 커지고 있는 추론(Reasoning) 수요 때문에도 중요하다. ‘사고의 사슬(CoT)’에 기반한 추론은 여러GPU 묶음 속에서 고대역폭 메모리를 얼마나 빠르고 원활하게 공유하느냐에 따라 성능이 달라진다.
피터 오누프리크 UA링크컨소시엄 회장은 “UA링크 200G 1.0 사양 발표를 통해 UA링크 컨소시엄 히원사는 확장형 가속기 연결을 위한 개방형 생태계를 적극적으로 구축하고 있다”며 “곧 시장에 출시돼 미래의 AI 애플리케이션을 지원하는 다양한 솔루션을 만나게 될 것”이라고 밝혔다.
엔비디아는 대외적으로 UA링크에 크게 주목하지 않는 모습이다. 젠슨 황 엔비디아 CEO는 작년 “UA링크 1.0이 나올 시점이면 NV링크는 6이나 7세대에 이를 것”이라고 자신감을 표시했다. 실제로 지난달 GTC 2025에서 엔비디아는 GPU 144개를 상호연결하는 NV링크5를 올해 출시하고, 내년 6세대 NV스위치와 7세대 NV스위치를 출시한다고 밝혔다. 2027년엔 NV링크6와 8세대 NV스위치가 나올 예정이다.
성능에서 UA링크는 아직 NV링크에 못미친다. UA링크 1.0의 대역폭은 200GTps라고 한다. 초당 기가바이트(GBps)라는 엔비디아 NV링크와 표기가다르다.
GTps는 ‘Giga Transfers per Second’이며, 초당 10억개의 신호를 전송한다는 의미다. 물리적 통신 채널을 통한 원시 신호 전송률이다. GBps는 오버헤드를 제외한 실제 유효 데이터 처리량을 의미한다.
UA링크 1.0 4개 레인의 최대 성능을 엔비디아와 비슷한 방법으로 계산하면 실제 유효 데이터 전송률은 100GBps가 된다. 양방향 합산 약 200GBps 대역폭을 제공하는 것이다. NV링크4는 양방향 합산 시 최대 900GBps다.
글. 바이라인네트워크
<김우용 기자>yong2@byline.network