
2차전 시작한 생성AI 대전…뜨거워진 LLM 경쟁
“눈에 띄지 않았던 친구 A가 갑자기 공부를 잘하기 시작했다. 좋은 성적을 내니 너도나도 친하게 지내자며 손을 내민다. 부잣집 아이 B가 이 친구를 독려하고 과외까지 받아 세상의 칭찬을 받기 시작했다. 원래 잘나가던 친구 C는 당황했다. 번뜩인다는 소리를 듣던 D도 절치부심해 반드시 A를 이겨야겠다고 마음먹었다.”
현재 생성 인공지능(AI) 대전에 참전한 테크 기업들의 관계도다. A는 오픈AI, B는 마이크로소프트다. 잘나가던 친구 C는 구글, 번뜩이는 D는 메타다.
챗GPT가 쏘아 올렸던 생성AI 기술 경쟁이 다양한 거대 언어모델(LLM) 출시로 새 국면을 맞았다. 단순한 파라미터 수 경쟁을 넘어 각자의 개성을 바탕으로 시장의 요구를 흡수하는 상황. 후발주자들의 매서운 추격이 오픈AI 천하였던 시장에 파도를 일으키고 있다.

오픈AI 치고 나가니 원조 강자들 절치부심
스타트업인 오픈AI는 지난해 11월 챗GPT로 그야말로 돌풍을 일으켰다. 텍스트로 세상의 정보를 수집해 정리해주는 챗GPT에 세상의 눈길이 쏠렸다. 챗GPT의 근간은 오픈AI가 개발한 LLM인 GPT다. 현재 GPT-4 버전까지 공개된 상태다. 오픈AI에 대규모 투자를 진행했던 마이크로소프트는 이를 접목한 솔루션을 속속들이 내놓으며 주가가 사상 최고치를 찍는 등 재미를 봤다.
하지만 GPT 모델의 아버지나 마찬가지인 구글 입장에서는 오픈AI의 약진이 속쓰린 일이었다. 잘나가는 GPT의 개념을 처음 고안한 게 혁신의 아이콘 구글이었다. GPT는 Generative Pre-trained Transformer의 약자로, 구글은 2017년 논문을 통해 해당 개념을 처음 세상에 소개했다.
구글은 지난 5월 새로운 LLM ‘팜(Palm)2’를 공개하고 반격에 나섰다. 지난해 발표했던 팜1의 후속모델이다. 선구자에서 추격자로 위치가 바뀐 상황. 특히 팜2는 수학적 추론이 강하다는 게 구글의 설명이다.
특히 팜2는 코딩에 강점을 보이는데, 파이썬(Python)이나 자바스크립트(JavaScript)와 같은 언어를 비롯해 20여개의 개발 언어를 이해하고 수행할 수 있는 게 특징이다. 서로 다른 코드로의 전환도 지원해 개발자 입장에서는 생산성을 획기적으로 높이는 계기가 될 수 있다.
최근 한국에서 열렸던 ‘대한민국 인공지능 위크 2023’ 발표에 나선 최현정 구글 바드 디렉터는 “코딩 추론을 월등히 향상시킨 모델”이라며 “AI를 실생활에 (더 많이) 이용할 수 있을 거라 기대한다”고 강조했다.
100개 이상의 언어를 학습해 높은 이해도를 보이는 것도 팜2의 장점이다. GPT를 쓴 챗GPT도 영어를 비롯해 한국어 프롬프트 입력과 결과 출력이 가능하지만 학습한 데이터 대부분은 영어라는 한계가 있다.
이에 다양한 언어의 데이터를 학습시켜 더 풍성한 답을 제공하고 오류를 줄인다. 팜2를 사용한 챗봇 ‘바드(Bard)’는 영어와 한국어를 지원한 데 이어 추후 40개 이상의 언어를 지원할 방침이다.

메타(구 페이스북)도 LLM 경쟁에 본격 참전을 선언했다. 메타의 최신 LLM인 라마(LLaMa)2의 가장 큰 특징은 오픈소스라는 점이다. 소스를 누구나 확인하고 수정할 수 있어 응용프로그래밍인터페이스(API) 활용 비용 확보가 어려운 중소기업이나 스타트업도 누구나 생성AI 기술에 접근하는 길을 열었다. 이전 버전인 라마1보다 40% 더 많은 2조개의 토큰을 학습했으며, 파라미터는 각각 70억개, 130억개, 700억개의 3가지 모델로 제공해 선택의 폭을 넓혔다.
하지만 기술 문서를 보면 라마2의 연산이나 프롬프트 입출력 성능 자체는 GPT와 팜2보다 떨어진다. 메타도 여전히 격차가 있다고 인정한다. 실제 모델 성능을 평가하는 대규모 다중작업 언어 이해(MMLU) 벤치마크에서 GPT, 팜2 모두에게 뒤처지는 결과를 냈다.
메타는 또한 마이크로소프트의 클라우드 애저(Azure)를 통해 라마2를 제공하기로 했다. 자체 클라우드가 없는 메타의 고육지책이면서도 묘수다.
LLM 후발주자인 메타 입장에서는 마이크로소프트의 인프라를 활용해 외연을 넓히는 한편, 마이크로소프트도 현재 오픈AI와의 동맹에 더해 메타를 애저에서 제공해 클라우드 사용료 수입을 기대할 수 있다.
국내 기업도 자체 LLM 출사표
한국도 LLM 2차대전에 출사표를 냈다. 가장 먼저 치고 나간 건 LG AI연구원의 엑사원(EXAONE)이다. 최근 2.0 모델을 공개했다. 엑사원 2.0은 한국어와 영어를 동시에 이해하고 답변할 수 있는 이중 언어(Bilingual) 모델로 개발했다. ‘Expert AI for EveryONE’이라는 엑사원의 어원처럼 LLM을 통해 효율을 높이려는 전문가에게 도움을 주는 LLM이라는 게 회사의 설명이다.
특히 이제까지 외국의 LLM이 해내지 못했던 멀티모달 AI을 표방한다. LG AI연구원 측은 “파트너십을 통해 확보한 약 4500만건의 특허·논문 등의 전문 문헌과 3억500만장의 이미지를 학습해 언어와 이미지를 동시에 이해할 수 있다”고 밝혔다.
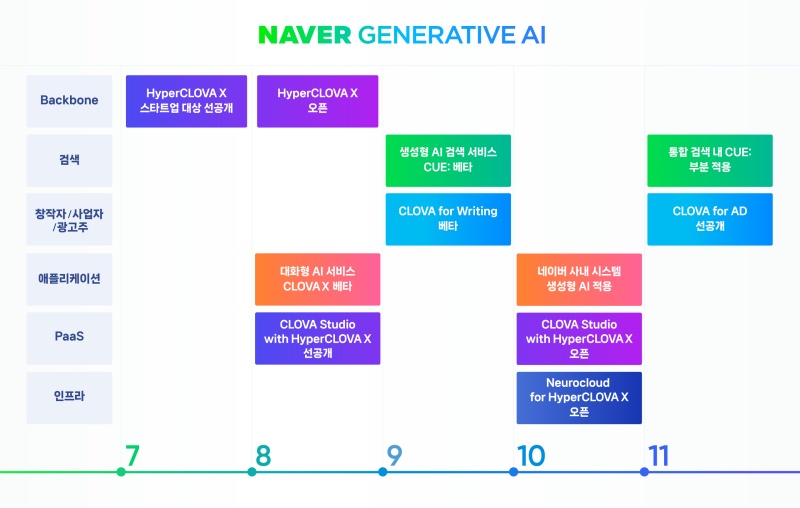
현재 가장 기대를 모으는 건 8월24일 출시가 예고된 네이버의 ‘하이퍼클로바 X’다. 자세한 기술 스택은 아직 공개되지 않았지만 여타 외산 LLM 만큼의 성능 이상이 될 거라는 전망이 나온다. 한국어를 가장 잘 이해하고 사용하는 LLM으로, 빅테크의 솔루션보다 품질도 더 높을 거라는 게 네이버의 전언이다.
9월에는 이를 활용한 검색 서비스인 ‘큐:(Cue:)’의 베타서비스도 시작한다. 네이버 관계자는 “복합적인 의도가 포함된 긴 질의를 이해하는 게 큐:의 핵심 기능”이라고 밝혔다.
카카오 또한 올 하반기 한국어 특화 LLM인 ‘코(KO)GPT’의 2.0 버전 공개를 목표로 개발을 진행하고 있다. 이를 활용한 챗봇 솔루션인 코챗GPT도 하반기 중 공개할 예정이다.
글. 바이라인네트워크
<이진호 기자>jhlee26@byline.network