효성인포메이션 “AWS S3같은 데이터레이크, 온프레미스·하이브리드 환경에서도 구축 가능”
‘데이터는 21세기의 원유’라고 할만큼 데이터의 중요성이 커지면서 많은 기업들은 수많은 빅데이터 프로젝트를 진행했다. 웬만한 기업들은 전통적인 데이터웨어하우스(DW)를 거쳐 한 때 빅데이터 열풍을 일으킨 주역이라 할 수 있는 하둡(Hadoop) 기반의 대용량 데이터 분산 저장·처리·분석 플랫폼을 운영하고 있다.
그런데 과연 이들 기업들은 필요한 데이터를 빠르고 효과적으로 분석해 비즈니스에 활용하고 있을까? 이 물음에 답이 될 수 있는 조사 결과가 있다.
수많은 빅데이터·데이터레이크 프로젝트 ‘실패’

권동수 효성인포메이션시스템 전문위원은 최근 바이라인네트워크가 개최한 ‘엣지 투 클라우드 데이터레이크 분석 전략’ 웨비나에서 포레스터리서치, 맥킨지, 가트너의 조사결과를 인용해 “기업당 평균 8개의 데이터 레이크가 존재하고 있다. 그런데 전체 데이터의 1%만 분석되고 있다고 한다. 빅데이터·데이터레이크 프로젝트가 실패한 사례가 많다”고 말했다.
 그 이유로 권 전문위원은 “여러 데이터레이크가 존재한다. 서로 다른 접근방식으로 처리하고 있다”며 “데이터에서 인사이트를 도출하려면 데이터가 어디에 있던지 쉽게 접근해 가져올 수 있어야 하는데, 너무 많은 저장소로 복잡하게 구성돼 있어 정작 1%의 데이터만 분석하고 있는 것”이라고 지적했다.
그 이유로 권 전문위원은 “여러 데이터레이크가 존재한다. 서로 다른 접근방식으로 처리하고 있다”며 “데이터에서 인사이트를 도출하려면 데이터가 어디에 있던지 쉽게 접근해 가져올 수 있어야 하는데, 너무 많은 저장소로 복잡하게 구성돼 있어 정작 1%의 데이터만 분석하고 있는 것”이라고 지적했다.
이어 “하둡, DWDM을 구축하고 있는 곳도 대부분 정형 데이터이고 비정형 데이터는 특수한 곳들을 빼고는 거의 활용하지 못하고 있다. 빅데이터 프로젝트를 한 기업의 분석가들도 머신러닝 기반 분석을 할 수 있는 데이터가 없다고 하는 실정”이라며 “아키텍처와 목적성 부재, 시스템과 기술 이해도가 낮은 것이 큰 원인”이라고 분석했다.
갈수록 데이터 종류와 형태가 다양해지고 또 비정형 데이터의 양도 급증되는 동시에 복잡성이 가중되는 데이터 관리 시스템 환경의 어려움을 해결할 수 있는 방법이 있을까. 권 위원은 먼저 그 해답의 실마리를 아마존웹서비스(AWS) S3에서 찾을 수 있다고 제시했다.
권 위원은 “초창기에는 데이터를 모으고 업무에 맞게 나눠 저장하기 위해 DW, 하둡, NoSQL에 NAS(Network Attached Storage)를 빅데이터 통합 플랫폼 구축에 사용했다. 모든 데이터의 형태를 다 담을 수 없었기 때문에 각 용도에 맞게 만든 저장소”라며 “그런데 AWS는 이 그림을 깼다. 하둡과 DW에 데이터를 바로 저장하는 방식이 아니라 중간에 새로운 저장소인 오브젝트 스토리지를 놨다. 이 오브젝트 스토리지가 S3이다. 이를 데이터 레이크라고 부른다”고 설명했다.
오브젝트 스토리지 기반 유연한 데이터레이크 아키텍처
NAS 대비 오브젝트 스토리지 기반의 데이터레이크의 차이점이자 장점으로 권 위원은 “오브젝트 스토리지는 메타데이터를 자동으로 관리한다. 각각 떨어져 있는 정보를 관리하기 때문에 다른 쪽에 활용하기 쉽다. 데이터가 들어올 때마다 각각 새로운 정보들을 메타데이터베이스(DB)화해 관리하고, 자동으로 생성된 것 외에 커스텀 메타정보를 관리할 수 있어 정형·반정형 데이터에 관계없이 다양한 형태의 데이터를 쉽게 찾고 관리할 수 있다”고 말했다.
권 위원은 “오브젝트 스토리지가 중간에 있으면 레거시 시스템을 거치지 않고 각각 필요한 저장소로 찾아갈 수 있다. 새로운 레거시 시스템이 추가돼 데이터가 쌓인다고 해도 하둡이나 DW 등과 같은 저장소를 고민하지 않고도 새로운 분석 DB가 나오더라도 모든 데이터를 일단 오브젝트 스토리지에 담아 가져올 수 있다는 것”이라며 “기존 레거시 시스템이나 분석 DB의 확장에 영향 받지 않고 처리할 수 있는 데이터레이크 시스템으로, 매우 유연한 아키텍처가 구성되기 때문에 중요하다”고 강조했다.
아울러 “만일 DW 에코시스템을 통해 데이터 마트를 생성해 시각적인 분석을 원한다면 S3에서 REST 애플리케이션프로그래밍인터페이스(API)를 사용해 필요한 정보를 대시보드로 볼 수 있다”고 예를 들어 덧붙였다.
이같은 아키텍처와 시스템을 AWS 클라우드 환경에서뿐 아니라 온프레미스·하이브리드 클라우드 환경에서도 만들 수 있다는 것이 권 위원의 얘기다. 갈수록 급증하는 데이터 저장·관리 비용은 줄이면서 안정적인 성능으로 처리·분석할 수 있는 환경을 구축할 수 있다.
오브젝트 스토리지와 데이터 검색·카탈로그, API 기반 연계 기능 제공
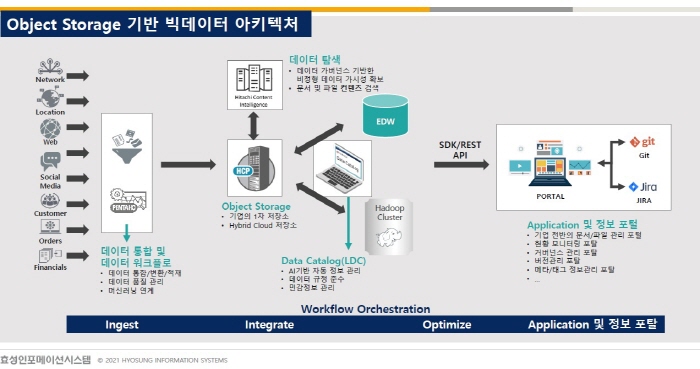 효성인포메이션시스템은 ▲다양한 데이터를 저장할 수 있는 오브젝트 스토리지 솔루션인 ‘히타치 콘텐트 플랫폼(HCP)’과 ▲데이터 플로우 커넥터를 제공하는 빅데이터 분석 플랫폼 ‘펜타호’, ▲인공지능(AI) 기반 체계적인 데이터 관리를 지원하는 ‘루마다 데이터 카탈로그’, ▲비정형 데이터 가시성 확보 솔루션인 ‘히타치 콘텐트 인텔리전스’ 등으로 유연한 데이터레이크 및 빅데이터 분석 아키텍처 구축을 지원한다.
효성인포메이션시스템은 ▲다양한 데이터를 저장할 수 있는 오브젝트 스토리지 솔루션인 ‘히타치 콘텐트 플랫폼(HCP)’과 ▲데이터 플로우 커넥터를 제공하는 빅데이터 분석 플랫폼 ‘펜타호’, ▲인공지능(AI) 기반 체계적인 데이터 관리를 지원하는 ‘루마다 데이터 카탈로그’, ▲비정형 데이터 가시성 확보 솔루션인 ‘히타치 콘텐트 인텔리전스’ 등으로 유연한 데이터레이크 및 빅데이터 분석 아키텍처 구축을 지원한다.
권 위원은 “HCP로 정형·비정형·반정형 데이터를 한 곳에 모을 수 있는 시스템을 제공한다. 데이터플로우 커넥터를 제공하며 카프카(Kafka)에 있는 정보까지 다 취합해 오브젝트 스토리지로 전달해줄 수 있다. 비정형 데이터 텍스트 기반 검색을 지원하는 히타치 콘텐츠 인텔리전스, 소프트웨어개발키트(SDK)와 REST API를 제공해 다른 시스템과 쉽게 연동할 수 있도록 제공한다”고 설명했다.
이에 더해 “데이터 저장소가 늘어나면 가장 고민되는 것이 데이터 위치를 찾는 것”이라면서 “‘루마다 데이터 카탈로그’ 솔루션은 하둡에 있는 데이터를 미국에서 특허 받은 핑거프린트 기술로 학습해 태깅하고 해당 정보를 검색할 수 있는 기술을 제공한다”고 부각했다.
권 위원은 “효성인포메이션은 AWS S3가 등장하기 전부터 오브젝트 스토리지를 관련 하드웨어와 소프트웨어, 서비스를 제공해왔다. 물론 AWS S3 API를 비롯한 클라우드 기술도 접목해 제공한다”며 “전체 데이터 파이프라인을 지원하는 펜타호를 주축으로 특정 기술과 플랫폼에 종속되지 않은 개방형 플랫폼을 제공하고 있다”고 강조했다.
글. 바이라인네트워크
<이유지 기자>yjlee@byline.network
첫 댓글